
From Clicks to Security: Investigating Continuous Authentication via Mouse Dynamics
Source: arXiv:2403.03828 · Published 2024-03-06 · By Rushit Dave, Marcho Handoko, Ali Rashid, Cole Schoenbauer
TL;DR
This paper asks whether mouse movement dynamics can support continuous authentication, and whether model performance changes when the user is interacting in two very different contexts: a low-intensity strategy game (Poly Bridge) and a high-intensity shooter (Team Fortress 2). The core idea is not novel at the “mouse dynamics exist” level; instead, the paper is trying to stress-test the modality across interaction regimes and compare sequence models against classical tree-based classifiers.
The study’s main result is that the recurrent models, especially GRU, generalize best across both games, while Decision Tree and Random Forest fit the training data too aggressively and lose more performance at test time. In their combined dataset evaluation, GRU and LSTM stay around AUC 0.97 on test, while RF drops to about 0.91 AUC despite perfect or near-perfect training scores. The authors interpret this as evidence that mouse dynamics are a viable signal for continuous authentication, with GRU being the most consistent model in their setup.
Key findings
- Across the combined Poly Bridge + TF2 setting, GRU holds test AUC at 0.97 and test ROC at 0.96, outperforming RF’s test AUC of 0.91 and ROC of 0.85.
- On TF2, GRU averages train/test AUC of 0.99/0.99 and test F1 of 0.99, while LSTM averages 0.97/0.97 AUC and 0.88 test ROC.
- On Poly Bridge, GRU averages train/test AUC of 0.98/0.98 and test F1 of 0.98, while LSTM averages 0.97/0.96 AUC and 0.90 test F1.
- Decision Tree overfits consistently: in the combined dataset its training AUC is 1.00 but test AUC is 0.90 and test ROC is 0.63.
- Random Forest also overfits: in TF2 its training AUC is 1.00 but test AUC is 0.90 and test ROC is 0.71; in Poly Bridge its test AUC is 0.92 and test ROC is 0.94.
- The paper reports that 19 students contributed data, with 15 participants per game and 11 participants overlapping both games.
- The final feature set used for modeling is 8 variables: X, Y, Stop Duration, Jerk, Direction Change, Movement Distance, Acceleration, Button Presses, and Angle.
- The authors compare their GRU/LSTM AUCs against prior mouse-dynamics work cited in Table 1, including 0.953 AUC (Ciaramella et al., 2022), 0.94 AUC (Antal et al., 2021), and 0.981 AUC (Salman & Hameed, 2019), and claim competitive performance.
Threat model
The adversary is an unauthorized user who gains access to the session and attempts to masquerade as the legitimate account holder based on mouse behavior. The system assumes the legitimate user’s mouse dynamics have enough consistency to be learned, while the attacker does not have that behavioral pattern. The paper does not explicitly model adaptive mimicry, injected synthetic mouse traces, or other active evasion strategies, and it does not state whether the attacker can observe the target user’s prior sessions.
Methodology — deep read
Threat model and framing: the paper treats continuous authentication as a binary verification problem. In the experimental framing, one designated legitimate user is labeled as the authentic user and all others are labeled as potential impostors. The text explicitly says user 18 is labeled 0 and other users are labeled 1 for the intrusion/authentication task. That means the model is not doing closed-set identification of all users at once; it is learning a one-vs-rest verifier for a target account. The paper does not deeply formalize attacker capabilities beyond the standard continuous-authentication assumption: the attacker can use the session but does not have the legitimate user’s behavioral signature. There is no explicit discussion of mimicry attacks, replay, or adversarial adaptation.
Data provenance and collection: the dataset was collected from 19 college students from Minnesota State University, Mankato, spanning undergraduate and graduate levels and multiple fields of study. A notable subset were computer-science students. Of those 19 participants, 11 played both games; the remainder were split across the two games, yielding 15 participants per game. The two games were chosen deliberately to create distinct interaction regimes: Poly Bridge as the low-intensity, deliberative environment, and Team Fortress 2 (TF2) as the high-intensity, fast-response environment. Each session lasted 15 minutes and used the same standardized computer setup, including identical mice and monitors, to reduce hardware-induced variance. The recorded raw events include timestamps, cursor X/Y coordinates, mouse button state, and duration values, as shown in Table 2. The paper does not provide the total number of raw events, total sequences, or an exact train/test split ratio in the excerpt; it only says the data were sequenced and cross-validation was used.
Feature engineering and preprocessing: the pipeline begins with cleaning to remove inconsistent or erroneous records, followed by feature extraction, normalization, and sequencing. The paper says features were statistically tested for relevance and interrelations, but it does not report the exact tests or p-values. It also says redundant features were removed: velocity was dropped because it was considered redundant with movement distance, and the binary Is_Stop feature was removed in favor of Stop_Duration. The final feature set is X and Y coordinates, Stop Duration, Jerk, Direction Change, Movement Distance, Acceleration, Button Presses, and Angle. Some derived rows had nulls or zeros, especially the first and last row of each user segment because those features depend on neighboring events; those rows were omitted. The data were then chunked into sequences of 40 data points, chosen to roughly match average session length and to balance temporal capture with computational cost. For tree models, the sequential data were flattened into a tabular representation, while GRU and LSTM consumed the 40-step sequences directly.
Architecture / algorithm: the paper compares four models: GRU, LSTM, Decision Tree, and Random Forest. GRU and LSTM are used as sequence learners to exploit temporal dependencies in mouse movement patterns. The excerpt does not specify layer counts, hidden sizes, activation functions, dropout, optimizer, loss function, learning rate, or early stopping criteria. Likewise, no architectural diagram beyond a high-level flow is provided. The Decision Tree and Random Forest are used as non-sequential baselines that operate on flattened inputs. The novelty is not a new neural architecture; it is the comparative use of recurrent vs classical models on the same behavioral biometric task across two interaction contexts.
Training regime and evaluation protocol: the paper says the models were developed using cross-validation, but does not specify the number of folds, whether splits were user-disjoint, or whether session-level leakage was prevented. That matters a lot for this task, because contiguous windows from the same user/session can inflate performance if not carefully separated. The reported metrics are AUC, ROC, and F1; the paper emphasizes AUC/ROC because the classes are imbalanced. For each game and for the combined dataset, Table 3–Table 6 report train and test scores by user (User20, User13, User4, User15, User8) and then an average. A concrete example: in TF2, User20’s GRU gets train/test AUC 0.99/0.99 and F1 1.00/1.00, while RF gets 1.00/0.90 AUC and 1.00/0.95 F1, showing strong fit on training but weaker generalization. The same pattern appears in Poly Bridge and the merged dataset. The authors interpret the lower test ROC for tree models as overfitting. The paper does not report statistical significance tests, confidence intervals, or variance across random seeds.
Reproducibility and reporting quality: the excerpt does not mention code release, frozen weights, or a public dataset. The dataset appears to be private, collected by the authors, and the full preprocessing/training details are incomplete in the excerpt. The paper provides useful high-level tables and qualitative plots (movement scatter and heatmaps in Figures 1–2, plus a model flow in Figure 3), but it leaves enough ambiguity that exact reproduction would require more implementation detail. One important point for readers: the reported performance is based on a small sample of 19 participants and appears to be evaluated on within-study data only, so the results should be read as a feasibility study rather than a hardened deployment benchmark.
Technical innovations
- Tests continuous mouse-dynamics authentication across two deliberately contrasting interaction regimes, low-intensity Poly Bridge and high-intensity Team Fortress 2, rather than a single task environment.
- Uses a compact feature set derived from raw mouse events and removes redundant variables such as velocity and Is_Stop to reduce multicollinearity and simplify modeling.
- Compares temporal models (GRU, LSTM) against non-temporal baselines (Decision Tree, Random Forest) on the same binary verification setup.
- Applies the same pipeline to a merged cross-environment dataset to assess whether user behavior remains stable enough for continuous authentication across contexts.
Datasets
- Poly Bridge — 15 participants, 15-minute sessions, 40-step sequences — authors’ own collection
- Team Fortress 2 — 15 participants, 15-minute sessions, 40-step sequences — authors’ own collection
- Combined (Poly Bridge + TF2) — merged from the two author-collected datasets, with 19 unique participants total and 11 overlapping across both games — authors’ own collection
Baselines vs proposed
- GRU vs LSTM on combined dataset: test AUC = 0.97 vs proposed (GRU) = 0.97
- Decision Tree on combined dataset: test AUC = 0.90 vs proposed (GRU) = 0.97
- Random Forest on combined dataset: test AUC = 0.91 vs proposed (GRU) = 0.97
- GRU on TF2: test AUC = 0.99 vs proposed = 0.99
- Random Forest on TF2: test ROC = 0.71 vs proposed (GRU) = 0.98
- GRU on Poly Bridge: test AUC = 0.98 vs proposed = 0.98
- Random Forest on Poly Bridge: test AUC = 0.92 vs proposed (GRU) = 0.98
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2403.03828.
Fig 1: Mouse Movement a) Poly b) TF2
Fig 2: Mouse Movement Heatmap a) Poly b) TF2
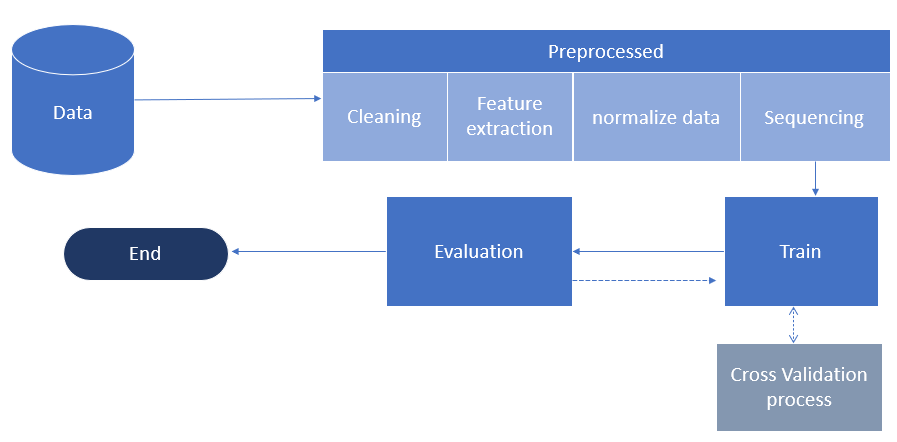
Fig 3: Model Flow
Limitations
- The study is small-scale: only 19 participants total, with 15 participants per game and 11 overlapping users, so the results may not generalize well.
- The excerpt does not specify exact model hyperparameters, optimizer settings, number of epochs, seed control, or fold count, which limits reproducibility.
- The evaluation appears to be within-study only; there is no external dataset validation or cross-site transfer test.
- The paper does not report attacker adaptation, mimicry, replay, or other stronger adversarial evaluations common in continuous-authentication research.
- Because the data were collected in games, it is unclear how well the learned signatures transfer to ordinary desktop, work, or mobile contexts.
- User-disjoint splitting is not clearly documented in the excerpt, so there is a risk that temporal windows from the same session/user could leak across train and test if not handled carefully.
Open questions / follow-ons
- Would the GRU advantage persist under user-disjoint and session-disjoint splits, or is some of the reported performance due to temporal leakage?
- How much of the signal comes from context-specific game mechanics versus user-specific motor behavior that would transfer to non-game desktop tasks?
- Would adding adversarial mimicry, replay, or pointer-injection attacks reduce the apparent AUCs substantially?
- Can the feature set be reduced further, or can raw-event models outperform handcrafted features on the same data?
Why it matters for bot defense
For bot-defense practitioners, the paper is mainly a feasibility signal: mouse movement contains enough behavioral regularity to support per-user verification, especially when the interaction context is stable. That suggests mouse telemetry can be part of a broader risk score for session continuity, but the results here are from a very small, homogeneous sample and from controlled gaming tasks, so they should not be interpreted as deployment-ready evidence.
In CAPTCHA and bot-defense systems, the practical takeaway is that mouse-dynamics models may help distinguish a returning human user from a fresh session or automation, but only if the evaluation is hardened against leakage and adaptive attackers. A bot engineer would want to test whether the same signals survive cursor replay, scripted motion with noise, pointer acceleration spoofing, and cross-domain shifts from games to normal web interactions. The paper’s strongest value is as a reminder that temporal behavioral signals can be highly discriminative — but also highly context-dependent.
Cite
@article{arxiv2403_03828,
title={ From Clicks to Security: Investigating Continuous Authentication via Mouse Dynamics },
author={ Rushit Dave and Marcho Handoko and Ali Rashid and Cole Schoenbauer },
journal={arXiv preprint arXiv:2403.03828},
year={ 2024 },
url={https://arxiv.org/abs/2403.03828}
}