
An Exploratory Analysis of COVID Bot vs Human Disinformation Dissemination stemming from the Disinformation Dozen on Telegram
Source: arXiv:2402.14203 · Published 2024-02-22 · By Lynnette Hui Xian Ng, Ian Kloo, Kathleen M. Carley
TL;DR
This paper studies how COVID-era disinformation from the “Disinformation Dozen” propagates on Telegram, and whether bots or humans are doing the main work of amplification. The authors build a 1-hop snowball sample starting from Telegram channels associated with the 12 CCDH-identified spreaders, then collect public messages, forwards, and replies from January through June 2023. They split users into three groups: the Disinformation Dozen seed accounts, bot users, and human users, and compare them along temporal, topical, and network dimensions.
The main contribution is not a new detector or classifier, but an exploratory measurement study of dissemination mechanics on Telegram. Their results suggest the Disinformation Dozen are the initial seeds of content, but not the main propagation engine: bots are highly active in discussion threads, while humans are the primary forwarders across channels. They also adapt BotBuster, a bot-detection method validated on X/Reddit, to Telegram and manually verify that it achieves 72% F1 on a labeled sample, which they treat as sufficient for the downstream analysis. The work is strongest as a platform-specific dissemination characterization, and weaker as a causal or generalizable study because it is limited to public Telegram channels, a narrow time window, and one-hop expansion from known seed accounts.
Key findings
- The study collected 7,711,975 messages from 10,633 public Telegram channels written by 335,088 unique users, covering January–June 2023.
- Only 8 of the 12 Disinformation Dozen had active Telegram accounts in early 2023; 6 of those 8 enabled discussions on their channels.
- BotBuster labeled 29.9% of non-seed users as bots and 70.1% as humans at a 0.5 threshold; manual verification on a stratified 0.1% sample (2,767 points) gave 72% F1.
- Manual annotation agreement was high: Cohen’s kappa between the first two annotators was 0.92.
- Bot and human posting-frequency time series were extremely similar, with Pearson correlation 0.983 (p = 4.05E-90).
- The Disinformation Dozen posted least frequently, bots and humans posted much more often, and bots/humans had similar temporal patterns (Fig. 4).
- The authors report that the Disinformation Dozen are the initial seeds of information, bots are most active in replies, and humans are the main forwarders across channels (Fig. 3 and network analysis section).
Threat model
The implicit adversary is a disinformation actor operating public Telegram channels and associated discussion threads, including the CCDH-identified Disinformation Dozen, inauthentic bot accounts, and human amplifiers who forward or reply to content. The study assumes the attacker can post publicly, forward messages between channels, and participate in discussion threads, but cannot hide from public channel collection, and the researchers do not assume access to private chats or non-public metadata. The paper does not model an active platform defender or an adversary who can evade all textual/network cues; instead it measures how much propagation is visible through public Telegram mechanics.
Methodology — deep read
Threat model and framing: this is not an adversarial security paper in the narrow sense, but it does implicitly assume an information-operation ecosystem with three actor classes: the Disinformation Dozen as known seed accounts, bots as inauthentic or automated amplifiers, and humans as authentic users who may still propagate falsehoods. The authors are not trying to identify a specific attacker with control over the dataset; instead, they study the observable dissemination behavior of public accounts on Telegram. They explicitly avoid private channels/chats and do not attempt to deanonymize users beyond the known Dozen, which limits the adversary model to public activity visible through Telegram’s API and forwarding/reply metadata.
Data collection: the dataset is built via manual discovery plus 1-hop snowball sampling. The authors first search Telegram for the CCDH “Disinformation Dozen” names and find 8 active Telegram accounts/channels. Of those, 6 enabled discussion groups, so both channel posts and discussion replies are collected. They then identify forwarded messages in posts/discussions, extract the source channel/user where the content was forwarded from, and collect messages from those source channels as a 1-hop expansion. Collection uses the Python Telethon API. The time window is January through June 2023, and the resulting corpus is 7,711,975 messages from 10,633 channels and 335,088 unique users. The paper says the data are almost exclusively English. Public channels only were accessed; no private chats were targeted. For privacy, user names are redacted in presentation.
User-group assignment is central to the study. The Disinformation Dozen labels are taken from the March 24, 2021 CCDH report. For bots, the authors adapt BotBuster, a bot-detection system previously trained and validated on X, Instagram, and Reddit. Because Telegram lacks some fields BotBuster can consume, they harmonize the available Telegram fields to the model’s expected schema and use whatever subset is present. Before doing so, they compare 3,000 random Telegram messages with 3,000 random X tweets from the same time period (tweets filtered by #covid and #vaccine) and report no statistically significant differences in message length or username/screen-name style at p < 0.05 using two-tailed t-tests. That comparison is used to justify transfer of the X-trained bot detector to Telegram. BotBuster outputs a bot probability in [0,1], with threshold 0.5 for bot vs human. To validate, they manually annotate a stratified 0.1% sample of the BotBuster output, yielding 2,767 labeled examples. Two authors label each item using usernames and messages; a third resolves disagreements. Cohen’s kappa between the first two annotators is 0.92, and the final gold labels are formed by majority vote (described as maximum pooling). They report 72% F1 for BotBuster against this gold sample, and use that classifier to label all remaining non-Dozen users.
Analytic pipeline: the paper then runs three analyses aligned with the research questions. First, temporal analysis: they aggregate message counts by day for the three user groups and visualize them in Fig. 4. They manually inspect the time series and then compute Pearson correlation between bot and human posting-frequency vectors, obtaining 0.983 with p = 4.05E-90. Second, topical analysis: they use BERTopic plus GPT-4 to cluster topics, and NetMapper to extract linguistic properties. The summarized topic findings in Fig. 3 are that the Disinformation Dozen skew toward natural health/healing and vaccine concerns, bots are associated with critiques and opinions, and humans are associated with discontent, conspiracies, and opinions. The paper also notes that the Dozen use “much lesser linguistic cues and themes” than bots and humans, though the excerpt does not provide the exact NetMapper feature list or quantitative deltas. Third, network analysis: they construct user-to-user graphs for forwarded-by and reply-by relationships to trace dissemination. This is used to support the claim that the Disinformation Dozen seed content, bots drive discussion via replies, and humans move content between channels via forwarding. The excerpt does not show the exact graph statistics (degree distributions, centralities, or edge counts), so those details remain unclear.
Reproducibility and one concrete walk-through: the collection method is reproducible in principle because it relies on public Telegram APIs and specific starting names from CCDH, but the paper does not mention code release, frozen bot-detection weights, or a public dataset release. The bot labeling step is the most methodologically sensitive piece: a concrete example would be a public Telegram user posting repeated short comments like “I agree with you” across multiple threads. BotBuster would process the available username/post/metadata fields, return a bot-likelihood score, and if the score is at least 0.5 the account is labeled bot; the manual annotation subset suggests many such repetitive, link-spamming, uppercase-heavy accounts are indeed bot-like. However, because the paper does not expose the exact feature subset available per Telegram user or the exact BotBuster variant used, full replication would require implementation details not present in the excerpt. Similarly, the topic model hyperparameters, BERTopic configuration, and GPT-4 prompting protocol are not specified in the provided text, so those components are only partially reproducible from the paper as excerpted.
Technical innovations
- Adapts BotBuster, originally validated on X/Reddit, to Telegram by restricting it to Telegram-available fields and checking cross-platform message/username statistics before transfer.
- Combines seed-user tracing, forwarding provenance, and discussion-reply graphs to separate initiation from propagation on Telegram instead of treating all activity as homogeneous amplification.
- Uses a 1-hop snowball collection from known disinformation accounts to recover the first layer of downstream channels receiving forwarded content.
- Pairs unsupervised topic clustering (BERTopic) with GPT-4-assisted topic interpretation and NetMapper linguistic analysis for a three-group comparison.
Datasets
- Telegram public COVID-disinformation corpus — 7,711,975 messages, 10,633 channels, 335,088 users — collected via Telethon from public channels/groups and 1-hop forwarded-to channels
- Telegram bot-verification sample — 2,767 labeled user datapoints (0.1% stratified sample) — manually annotated from the Telegram corpus
- Cross-platform comparison sample — 3,000 Telegram messages and 3,000 X tweets — X tweets collected via streaming API filtered for #covid and #vaccine
Baselines vs proposed
- BotBuster (adapted to Telegram): manual-annotation F1 = 72% vs proposed: 72%
- BotBuster original fine-tuned on Twitter: F1 = 73% vs proposed on Telegram: 72%
- Bot vs human posting frequency: Pearson correlation = 0.983 (p = 4.05E-90) vs proposed: 0.983 (significant positive correlation)
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2402.14203.

Fig 1: Data Collection Pipeline

Fig 2: User Group Identification Pipeline
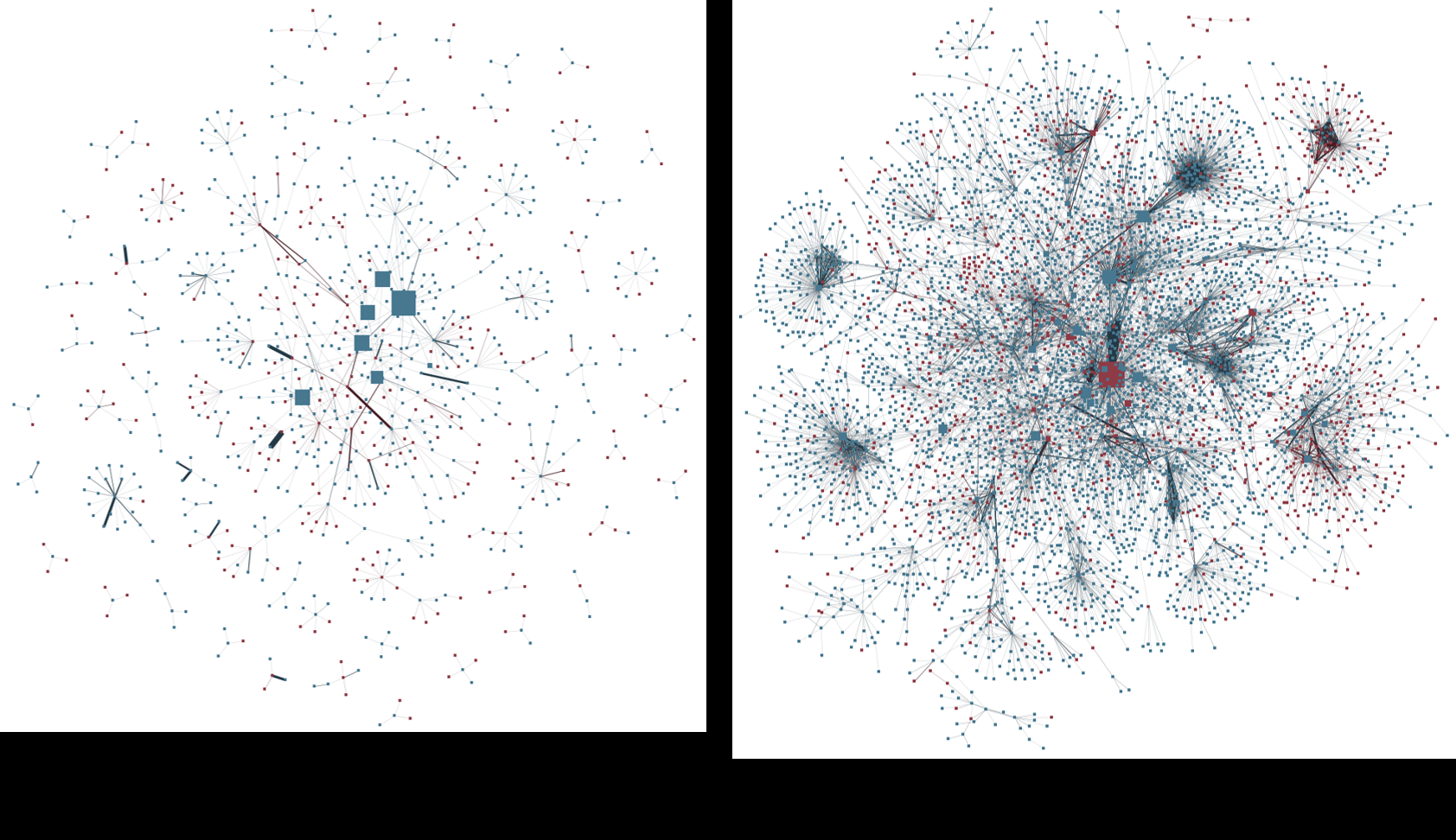
Fig 7: Network graphs of User-User interaction with the Forward and Reply mech-
Limitations
- The bot detector is only validated on a stratified 0.1% sample; 72% F1 is usable but not strong, so bot/human downstream labels are noisy.
- The dataset is limited to public Telegram channels and discussions; private chats and closed groups are excluded, so the network is incomplete.
- The expansion is only 1-hop from seed channels; longer propagation chains may be missed, and the sample is anchored to known CCDH accounts.
- The excerpt does not report detailed topic-model metrics, network statistics, or robustness checks for alternative thresholds or bot detectors.
- The time window is only January–June 2023, long after the original 2021 CCDH designation, so the findings may reflect post-ban migration dynamics rather than peak-pandemic behavior.
Open questions / follow-ons
- How much of the apparent bot activity persists under stronger bot detectors or multi-model ensemble labeling on Telegram-specific features?
- Does the 1-hop snowball from Disinformation Dozen accounts miss important downstream communities that receive the same content through non-forward pathways?
- Are bots primarily engaged in low-value engagement, or do they causally increase the reach of forwarded content into new channels?
- Do the temporal and topical patterns change across non-English Telegram communities or other post-2023 periods?
Why it matters for bot defense
For a bot-defense practitioner, the paper is a reminder that bot activity on Telegram may be visible less through posting volume alone than through interaction style: repetitive replies, link copying, and thread-level engagement can be stronger signals than sheer content originality. The 0.983 bot-human temporal correlation also suggests that synchronized activity spikes are not enough to separate authentic from inauthentic accounts in a crisis narrative; humans can mimic bot-like cadence and bots can ride human attention waves. If you were building defenses, the practical takeaway is to combine account-level signals with propagation-role signals: seed accounts, reply-heavy accounts, and forward-heavy accounts behave differently and should be scored differently rather than collapsed into one generic “amplifier” class. The biggest caution is that a moderately accurate bot classifier can still distort network conclusions if used uncritically, so any operational use would want confidence calibration, sensitivity analysis over the 0.5 threshold, and validation on Telegram-native ground truth before policy decisions.
Cite
@article{arxiv2402_14203,
title={ An Exploratory Analysis of COVID Bot vs Human Disinformation Dissemination stemming from the Disinformation Dozen on Telegram },
author={ Lynnette Hui Xian Ng and Ian Kloo and Kathleen M. Carley },
journal={arXiv preprint arXiv:2402.14203},
year={ 2024 },
url={https://arxiv.org/abs/2402.14203}
}