
Segmentation-free Connectionist Temporal Classification loss based OCR Model for Text Captcha Classification
Source: arXiv:2402.05417 · Published 2024-02-08 · By Vaibhav Khatavkar, Makarand Velankar, Sneha Petkar
TL;DR
This paper addresses the challenge of recognizing distorted, variable-length text captchas, which are commonly used to differentiate humans from bots in security settings. Traditional OCR methods struggle with captchas due to intentional distortions, variable sequence lengths, and complex character dependencies. To overcome these issues, the authors propose a segmentation-free OCR model that integrates Convolutional Neural Networks (CNNs) for spatial feature extraction, Recurrent Neural Networks (RNNs) to capture sequential dependencies, and Connectionist Temporal Classification (CTC) loss to handle variable-length sequences without explicit segmentation.
The model is trained and evaluated on a publicly available Kaggle captcha dataset consisting of 1040 images with 19 unique alphanumeric characters, including distortions, noise, and varying lengths. It achieves very high performance with 99.80% character-level accuracy and 95% word-level accuracy, outperforming several recent state-of-the-art approaches. The use of CTC loss allows alignment-free training on variable-length captchas, providing robustness against typical captcha challenges. The paper demonstrates that a segmentation-free OCR pipeline with CNN+RNN+CTC is effective for complex captcha recognition and suggests potential extensions with attention mechanisms, GAN-based augmentation, and transfer learning.
Key findings
- Proposed OCR model achieves 99.80% character level accuracy on the Kaggle captcha dataset with 1040 samples
- Word level accuracy of the model reaches 95%, surpassing recent state-of-the-art methods like 94% reported by Suke Kong (2023)
- Model handles variable-length captchas with CTC loss, removing need for explicit segmentation
- Dataset contains 19 unique characters including digits and letters with variable distortion and noise
- Training employs CNN for feature extraction, followed by RNN for sequential context modeling, and CTC loss for alignment-free sequence recognition
- Data augmentation (rotation, translation, flipping, zooming) applied to improve robustness
- Compared baseline CNN-RNN models without CTC show degraded performance (exact numbers unclear)
- Model training monitored via TensorBoard, showing steady convergence of CTC loss (Figure 5)
Threat model
The adversary is an automated system trying to break text-based captchas by recognizing distorted text images. The adversary can access the captcha images and attempt to classify the character sequences but does not have access to internal model parameters or training data. The system assumes the adversary cannot perfectly solve captchas without solving the OCR recognition challenge. This model focuses on improving OCR accuracy against such adversaries.
Methodology — deep read
The paper's OCR model is designed for text captchas with distortions, variable length, and sequential dependency challenges. The threat model implicitly targets automated bots attempting to break captchas; the adversary can access captcha images but not internal model parameters or training data.
The dataset is a publicly available Kaggle set containing 1040 captcha images labeled by the text string in the image. The dataset includes a diverse character set of 19 alphanumeric and special characters, with variable sequence lengths and noise/distortion. Data preprocessing involves image contrast enhancement, normalization to [0,1], noise reduction, and data augmentation (rotation, flipping, translation, zoom, shear, brightness, contrast adjustments). The labels are one-hot encoded. The dataset is split into roughly 70-80% training, 10-15% validation, and the remainder for testing.
The model architecture begins with convolutional layers (CNN) to extract spatial features from captcha images, effectively encoding visual patterns despite noise and distortion. The CNN output is reshaped into a sequence passed to a Recurrent Neural Network (RNN), which models sequential dependencies between characters in the captcha string. The RNN maintains hidden states capturing context at each step, critical due to distorted character adjacency.
A Connectionist Temporal Classification (CTC) loss layer is applied to the RNN output. CTC allows training on variable-length output sequences without explicit character segmentation or alignment by learning a probabilistic alignment between input features and output sequences. This removes the need for preprocessing steps like segmenting captchas into characters.
Training uses TensorFlow and Keras infrastructure on GPU hardware (hardware specs not specified). Hyperparameters such as learning rate, batch size, and number of epochs are tuned but exact values are not detailed. The training loss (CTC loss) steadily decreases, monitored via TensorBoard.
Evaluation metrics include character-level accuracy (percentage of correctly recognized characters) and word-level accuracy (percentage of fully correct captcha strings). The model is compared with multiple prior state-of-the-art methods (e.g. Nouri Z 2020, Jing Wang 2019, Suke Kong 2023), showing superior performance by 0.5-1% accuracy.
No explicit cross-validation or adversarial attack evaluation is reported. Code and detailed hyperparameters are not mentioned as released, thus exact reproducibility is unclear. The paper emphasizes end-to-end training from raw images to final text prediction without requiring segmentation, which simplifies captcha recognition pipelines.
Technical innovations
- Application of Connectionist Temporal Classification (CTC) loss in OCR captcha recognition to handle variable-length and unsegmented sequences
- Segmentation-free CNN+RNN architecture designed specifically for distorted, complex text captchas with sequential dependencies
- Integration of extensive data augmentation techniques (rotation, zoom, contrast adjustments) to improve model robustness on noisy captcha data
- Use of one-hot encoding and CTC decoding for efficient end-to-end training and prediction without explicit character segmentation
Datasets
- Kaggle Captcha Version 2 Images Dataset — 1040 samples — publicly available at https://www.kaggle.com/datasets/fournierp/captcha-version-2-images
Baselines vs proposed
- Nouri Z (2020): Character Level Accuracy = 98.94% vs proposed: 99.80%
- Jing Wang (2019): Character Level Accuracy = 99.70% vs proposed: 99.80%
- Bursztein E (2014): Character Level Accuracy = 51.1% vs proposed: 99.80%
- Ye G (2020): Character Level Accuracy = 51.6% vs proposed: 99.80%
- Suke Kong (2023): Word Level Accuracy = 94% vs proposed: 95%
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2402.05417.
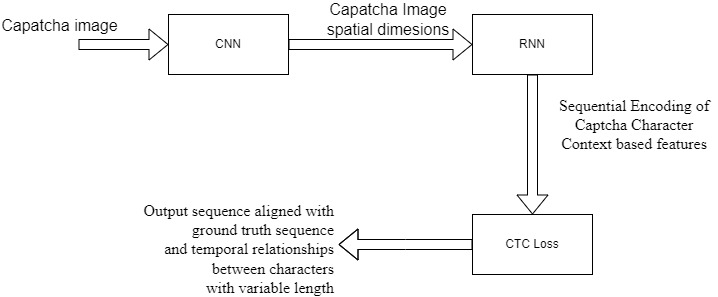
Fig 1: Proposed Model
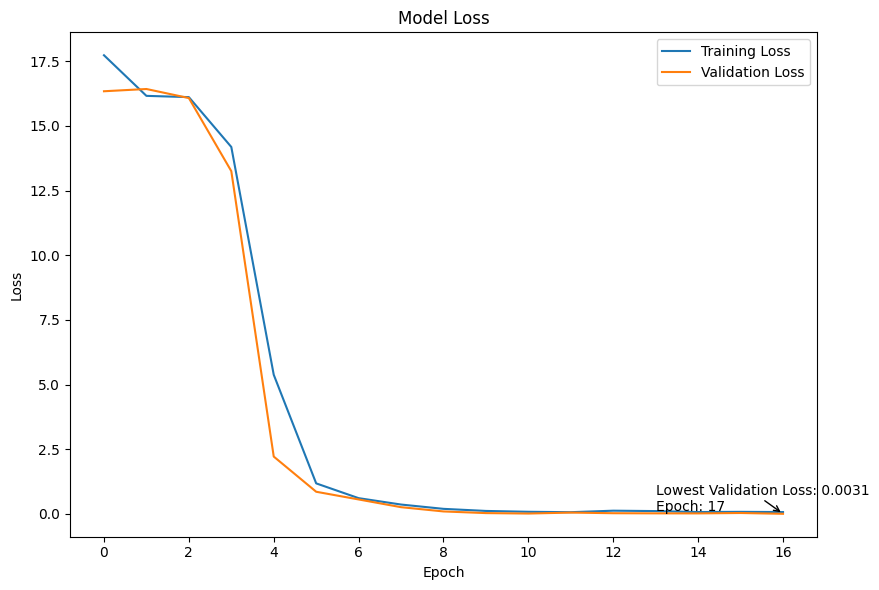
Fig 4: Training of model
Limitations
- Relatively small dataset size (1040 captcha images) may limit generalizability to diverse captcha styles
- No adversarial or bot attack robustness evaluation performed
- Limited detail on hyperparameter tuning and training regime impeding reproducibility
- Model evaluation confined to one dataset without testing on out-of-distribution or unseen captcha forms
- Handling of extreme distortion or overlapping characters not extensively analyzed
- No ablation study reported isolating contributions of CNN, RNN, and CTC loss components
Open questions / follow-ons
- How does the model perform under adversarial captcha attacks specifically designed to fool OCR systems?
- Can attention mechanisms or transformer-based architectures further improve recognition over the CNN-RNN-CTC pipeline?
- What benefits would synthetic captcha datasets generated by GANs bring for model robustness and generalization?
- How well does transfer learning from large-scale image/text datasets improve convergence and performance on captcha tasks?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, this work highlights the effectiveness of segmentation-free OCR based on CNN, RNN, and CTC loss for recognizing challenging text captchas with distortions and variable lengths. The model provides a practical pipeline that removes the need for manual character segmentation, simplifying OCR systems used in attacks or defenses. While the reported accuracy is very high on the Kaggle dataset, practitioners should note limitations like dataset size and lack of adversarial evaluation.
This research reinforces that captcha designs relying solely on distorted text may be vulnerable to modern deep sequence models with CTC-based training. Understanding these capabilities can guide captcha designers to adopt more resilient challenges or multimodal captchas. It also provides a benchmark approach for bot developers evaluating OCR attack strength against deployed captchas. Deployers should consider augmenting captcha tests with non-OCR-based signals due to the growing threat posed by segmentation-free OCR pipelines.
Cite
@article{arxiv2402_05417,
title={ Segmentation-free Connectionist Temporal Classification loss based OCR Model for Text Captcha Classification },
author={ Vaibhav Khatavkar and Makarand Velankar and Sneha Petkar },
journal={arXiv preprint arXiv:2402.05417},
year={ 2024 },
url={https://arxiv.org/abs/2402.05417}
}