
FP-Fed: Privacy-Preserving Federated Detection of Browser Fingerprinting
Source: arXiv:2311.16940 · Published 2023-11-28 · By Meenatchi Sundaram Muthu Selva Annamalai, Igor Bilogrevic, Emiliano De Cristofaro
TL;DR
This paper addresses the challenge of detecting browser fingerprinting, a privacy-invasive tracking technique increasingly used as third-party cookies are restricted. Prior detection approaches depend on centralized web crawls and expensive static analysis, which face issues such as inability to simulate realistic user browsing and heavy computational costs. FP-Fed is introduced as the first federated learning system for browser fingerprinting detection that trains models collaboratively on users' real browsing data without sharing raw data, preserving user privacy through Differentially Private Federated Learning (DP-FL).
FP-Fed relies on dynamic runtime signals extracted from JavaScript execution traces on-device rather than static features, enabling efficient local training and inference under resource constraints. It uses a logistic regression model trained via federated averaging with participant-level central differential privacy guarantees. The system is evaluated on a dataset of 18,300 popular websites and shows that with one million participants, it can achieve an AUPRC of 0.86 under strong privacy (ε=1) and up to 0.95 with weaker privacy (ε=10), close to centralized models accuracy. FP-Fed also outperforms local-only training baselines (0.78 AUPRC), demonstrating the benefits of federated training with privacy.
The study also investigates the impact of the number of participants, feature sets, and privacy levels, showing that a modest feature set of ~149 dynamic features suffices for competitive detection performance. By capturing real user browsing patterns rather than simulated crawls, FP-Fed is positioned as a practical, privacy-preserving system for robust browser fingerprinting detection in the wild.
Key findings
- FP-Fed achieves an AUPRC of 0.86 with 1 million participants and ε=1 (strong DP guarantee).
- At ε=10, FP-Fed attains 0.95 AUPRC, close to centralized model's 0.97 AUPRC.
- Local-only training on a user's data yields 0.78 AUPRC, significantly lower than federated training.
- Using just 149 dynamic features (out of 1,514 total) maintains competitive detection performance.
- Federated DP aggregation uses the FedAvg algorithm with Gaussian noise to ensure participant-level central DP.
- Real user data captures ~3x more fingerprinting scripts than automated crawlers on top 300 domains.
- FP-Fed training and inference require only runtime dynamic signals, avoiding costly static analysis and enabling on-device deployment.
- Preprocessing normalization statistics are aggregated in a DP manner before federated training.
Threat model
Adversaries aim to infer participants’ browsing patterns or identify users from model updates exchanged during federated learning. The server is honest-but-curious and trusted to perform differentially private aggregation but is not trusted with raw data. Participants share only model updates, not raw browsing data. The privacy guarantee is participant-level central differential privacy, protecting all data of a single user in aggregate. The system does not consider malicious participants or servers that deviate from the protocol.
Methodology — deep read
The threat model considers adversaries interested in inferring sensitive browsing behaviors or identifying individual users from the training data or model updates. The server is trusted to correctly perform differentially private aggregation but not trusted with raw user data. Participant-level central differential privacy is provided via adding Gaussian noise during server-side aggregation (CDP), bounding privacy leakage across all data per participant.
Data provenance stems from a large web crawl of 18.3k popular websites accessed via a Chrome-based browser instrumentation framework (Puppeteer) that records dynamic JavaScript execution traces including API call counts and argument/return values. The dataset captures scripts labeled as fingerprinting or non-fingerprinting via high-precision heuristics adapted from prior work (FP-Inspector). These heuristics cover Canvas, Canvas Font, WebRTC, and AudioContext fingerprinting forms, minimizing false positives but potentially allowing false negatives.
Feature extraction focuses on 1,514 dynamic features: 684 counts of JavaScript API calls identified as potentially fingerprinting-related (including 184 high-entropy APIs traced natively by Chrome) and 830 custom features derived from analyzing API call arguments and return values. Unlike static features such as ASTs, the dynamic features resist obfuscation and can be efficiently computed on-device.
Before training, each participant computes local means and variances of features clipped to fixed bounds. These summary statistics are shared with the server, which aggregates them with DP noise using the DP-FedNorm algorithm, then returns global normalization parameters for participant-level feature scaling.
FP-Fed uses a logistic regression model (sigmoid output neuron, no hidden layers) for simplicity and efficiency on device. Participants receive global model parameters at each round, perform local updates with stochastic gradient descent on their labeled scripts, clip and send model updates back to the server. The server performs DP aggregation of updates per the DP-FedAvg algorithm, adding calibrated Gaussian noise based on clipping norms and privacy parameters.
The training regime involves multiple rounds of federated averaging with batch updates from subsets of participants chosen probabilistically. The privacy parameters ε and δ are tracked via advanced composition and moments accountant to provide formal guarantees.
Evaluation metrics include Area Under the Precision-Recall Curve (AUPRC), comparing DP federated training against centralized training, local-only training, and varying participant counts and privacy budgets. Experiments also ablate feature subsets to assess trade-offs between instrumentation complexity and detection accuracy.
Reproducibility details are partial; the paper does not explicitly mention code release or trained models. The methodology robustly follows prior art on DP-FL and applies well-defined heuristics for ground truth labeling but acknowledges limitations such as reliance on heuristic labels and simulated browsing rather than fully distributed user data collection.
An example workflow: a participant visits websites, their instrumented browser extracts dynamic script execution features and locally labels scripts per heuristics, then normalizes features using global stats returned by the server. The participant trains a logistic regression model locally, clips gradients, and sends model updates. The server aggregates updates from many such participants with DP noise, updates the global model, and redistributes it for the next round, iterating until convergence.
Technical innovations
- First application of differential privacy based federated learning for browser fingerprinting detection from real user-like browsing data.
- Design of a decentralized feature normalization via differentially private federated aggregation (DP-FedNorm) to enable consistent on-device scaling.
- Demonstration that a modest set (~149) of dynamic runtime features suffices for high-accuracy fingerprinting detection under DP-FL, avoiding costly static analysis.
- Adaptation of participant-level central DP guarantees within federated averaging to bound privacy leakage while maintaining model utility.
- Use of dynamically instrumented Chrome APIs, including Chrome native high-entropy APIs, for robust feature extraction resistant to evasion.
Datasets
- Browser scripts dataset — 18,300 websites — web crawl using Chrome + Puppeteer
- Labeled scripts via FP-Inspector heuristics — size not explicitly reported but corresponds to scripts from crawl
Baselines vs proposed
- Local-only training: AUPRC = 0.78 vs FP-Fed (1M participants, ε=1): AUPRC = 0.86
- Centralized training (privacy agnostic): AUPRC = 0.97 vs FP-Fed (ε=10): AUPRC = 0.95
- FP-Fed varying participation — fewer participants degrade performance, e.g., at 100K participants AUPRC is lower (exact value not specified)
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2311.16940.
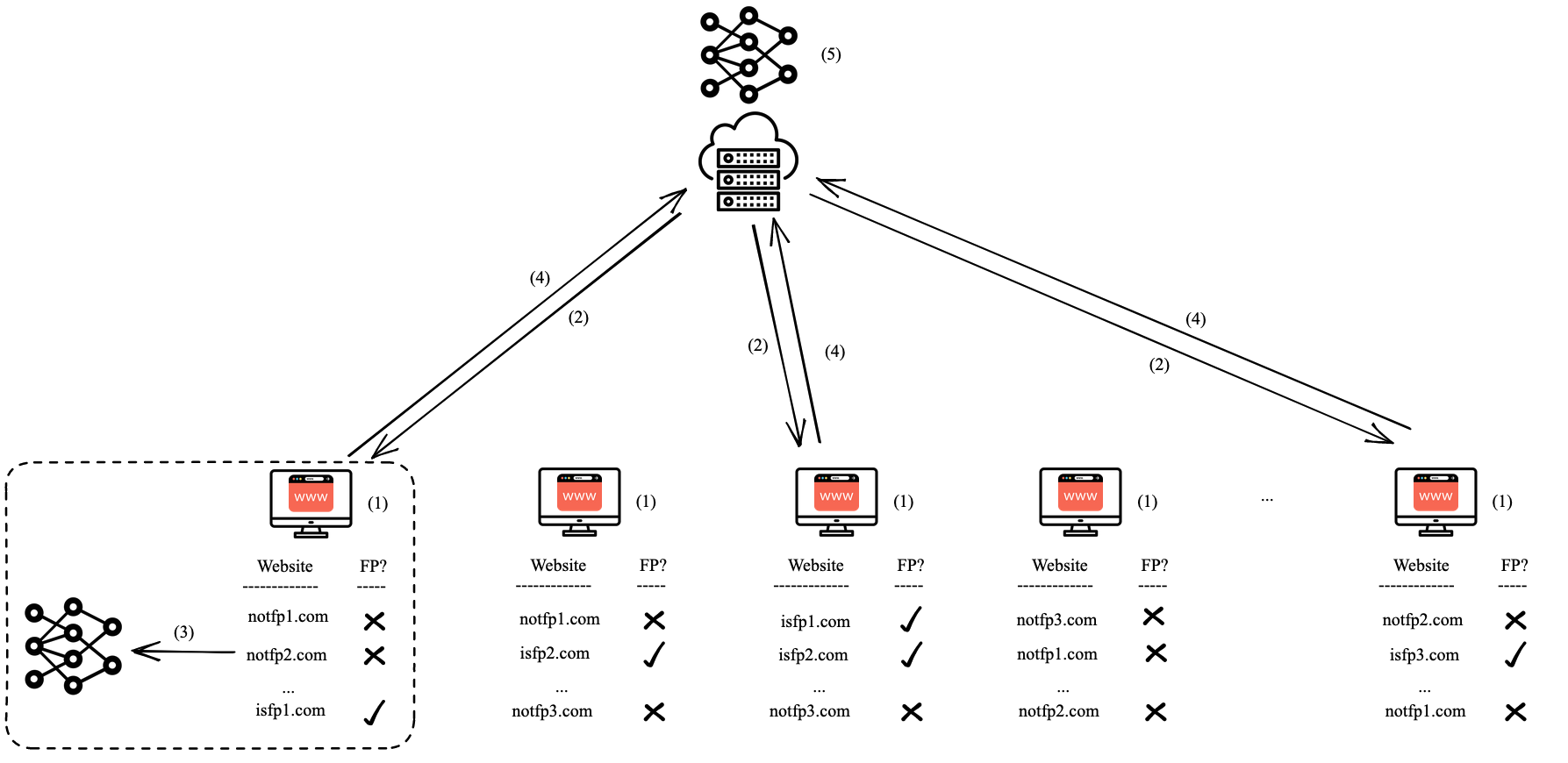
Fig 1: An overview of the FP-Fed system: (1) Participants collect execution traces from the websites they visit. (2) At each round of training,
Limitations
- Ground truth labels rely on high-precision heuristics that can yield false negatives, possibly missing unknown fingerprinting scripts.
- Evaluation is on crawl-collected data, not actual federated collection from live users over time — real-world deployment might reveal different distributions.
- The logistic regression model is simple; more complex models could improve accuracy but are not evaluated.
- The system assumes a trusted server for DP aggregation; adversarial or malicious servers are not considered.
- Latency, battery, and resource use implications on real devices are discussed but not experimentally quantified in user deployments.
- Secure aggregation and local DP alternatives are noted but not implemented, which may limit privacy threat models.
Open questions / follow-ons
- How would FP-Fed perform and scale in a fully deployed federated environment with real users over extended periods?
- Can more complex models such as neural networks improve detection while maintaining on-device efficiency and DP guarantees?
- How robust is the system against adversarial participants or model poisoning attacks within the federated setting?
- Can the DP-FedNorm normalization and DP aggregation protocols be extended or adapted to stronger local or distributed DP models with secure aggregation?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, FP-Fed offers a new paradigm for privacy-preserving detection of fingerprinting scripts based on real user browsing patterns rather than synthetic crawls. Its use of federated learning with differential privacy enables collaborative model improvement without exposing sensitive browsing histories, a common concern for anti-bot systems deployed at scale. By relying on lightweight dynamic features extracted from runtime JavaScript execution, FP-Fed supports efficient on-device inference, which could be integrated with client-side bot-detection mechanisms or risk scoring.
Furthermore, the approach illustrates how privacy guarantees can be balanced with detection utility—key for browser-based defenses deployed in privacy-sensitive contexts. Practitioners can glean insights on feature selection trade-offs, deployment scales needed for desired accuracy, and the privacy-utility frontier achievable in a federated fingerprinting detector. However, adapting FP-Fed to handle real adversaries, integrate with existing CAPTCHA workflows, or extend beyond fingerprinting detection to broader bot detection remains an open area.
Cite
@article{arxiv2311_16940,
title={ FP-Fed: Privacy-Preserving Federated Detection of Browser Fingerprinting },
author={ Meenatchi Sundaram Muthu Selva Annamalai and Igor Bilogrevic and Emiliano De Cristofaro },
journal={arXiv preprint arXiv:2311.16940},
year={ 2023 },
url={https://arxiv.org/abs/2311.16940}
}