
Continuous Authentication Using Mouse Clickstream Data Analysis
Source: arXiv:2312.00802 · Published 2023-11-23 · By Sultan Almalki, Prosenjit Chatterjee, Kaushik Roy
TL;DR
This paper studies continuous authentication from mouse clickstream data, using the Balabit Mouse Challenge dataset as a behavioral biometric source. The core question is practical rather than novel-algorithmic: can simple classical classifiers reliably distinguish a genuine user from impostors using hand-engineered mouse-action features, and does performance depend on the action type (mouse move, point-and-click, drag-and-drop) and evaluation setting? The authors frame this as a defense against session hijacking after initial login, where the system should keep checking whether the current mouse behavior still matches the enrolled user.
What is new here is not a new model family, but a structured empirical comparison across three off-the-shelf classifiers—Decision Tree, K-Nearest Neighbors, and Random Forest—under two authentication formulations: one-user-versus-impostors and all-users-with-one-action. The best reported results come from the point-and-click subset in the all-users setting, where KNN reaches 99.3% accuracy and 99.9% AUC. In the separate verification setting, all three classifiers are reported to achieve 100% accuracy, though the paper does not describe threshold selection or a more conservative operating-point analysis beyond the reported metrics.
Key findings
- The dataset contains 10 users; the evaluation uses users 7, 9, 12, 15, 16, 20, 21, 23, 29, and 35 in the reported tables, with 39 engineered features per mouse action.
- Verification mode (genuine-user-only training/testing) reports 100% verification accuracy for Decision Tree, KNN, and Random Forest across all users.
- In authentication scenario A (single user, all actions MM+PC+DD), average accuracy is 91.9% for Decision Tree, 94.4% for KNN, and 79.7% for Random Forest.
- In authentication scenario A, the average EER is 0.070 for Decision Tree, 0.012 for KNN, and 0.247 for Random Forest.
- In authentication scenario B, point-and-click (PC) is the strongest action subset: Decision Tree averages 87.6% ACC / 90.3% AUC, KNN 99.3% ACC / 99.9% AUC, and Random Forest 89.9% ACC / 92.5% AUC.
- For scenario B on mouse-move (MM), average ACC drops to 84.1% for Decision Tree, 99.4% for KNN, and 88.6% for Random Forest, with KNN still maintaining 99.8% AUC.
- For scenario B on drag-and-drop (DD), average ACC is 81.7% for Decision Tree, 98.9% for KNN, and 86.8% for Random Forest; the paper reports average EERs of 0.186, 0.021, and 0.138 respectively.
- Compared with the cited Antal et al. baseline on the same Balabit dataset, the paper claims better average performance for some configurations, but it does not present a direct side-by-side experiment on an identical split, so this comparison is not strictly controlled.
Threat model
The adversary is an impostor who tries to be accepted as a legitimate user during continuous authentication, using mouse activity that may resemble ordinary usage. The system is assumed to observe mouse clickstream features only, and the impostor is modeled as coming from the set of other users in the dataset. The paper does not address attackers who can deliberately mimic cursor behavior, replay captured traces, inject noise, or adapt to the classifier.
Methodology — deep read
Threat model and problem setup: the paper treats the adversary as an impostor who has access to the system after login or tries to be accepted as a genuine user during continuous monitoring. The system is assumed to observe only mouse behavior, not passwords or device tokens. The attacker model is weakly specified: the impostor is simply “other users” in the dataset, and the paper does not explore adaptive attackers, replay, or mimicry. The authentication task is framed in two ways: verification, where the system checks whether the current behavior matches a specific enrolled user, and authentication, where the system discriminates genuine from impostor behavior.
Data provenance and preprocessing: the work uses the Balabit Mouse Challenge dataset from the Budapest office of Balabit. The raw stream is described as rows of (rtime, ctime, button, state, x, y), where rtime and ctime are elapsed times recorded by network-monitoring and client-side clocks, and x/y are cursor coordinates. The paper says the dataset contains data for 10 users and 39 features per mouse action, and it uses the already-extracted features from Antal et al. rather than re-deriving them. Mouse behavior is partitioned into three action types: MM (mouse movement), PC (point-and-click), and DD (drag-and-drop). The paper does not report total number of sessions, total number of action instances, class balance, or whether any normalization/scaling was applied before training.
Architecture / algorithm: there is no neural architecture here; the model is a supervised classifier pipeline built around scikit-learn. The three evaluated learners are Decision Tree, k-Nearest Neighbors, and Random Forest. Inputs are the 39 features listed in Table 1, including action type, travelled distance, elapsed time, straightness, curvature statistics, angular velocity statistics, endpoint distance, critical points, velocity statistics, acceleration statistics, jerk statistics, and an initial acceleration-time feature. The paper’s novel component is essentially the experimental framing: it compares these classifiers across action subsets and two authentication scenarios. The authors state that training data are converted to CSV, then read into the classifiers, but they do not describe feature encoding details, distance metric choice for KNN, tree depth / number of trees for RF, or any feature selection. A concrete end-to-end example is: take all actions for user 9 in scenario A, aggregate the positive samples for that user and the negative samples from other users, split the prepared dataset 70/30, train KNN on the 70%, and evaluate on the 30%; for user 9 they report 99.2% ACC and 99.1% AUC for KNN in Table 2.
Training regime and evaluation protocol: the paper says the data were randomly ordered and split 70% train / 30% test, with the same balance preserved across experiments “to avoid classifier bias.” It does not report repeated runs, seeds, cross-validation, or hyperparameter tuning. Verification experiments train on a user’s genuine actions only and then test whether later samples are accepted. Authentication experiments use both genuine and impostor actions and are organized into two scenarios: (A) one user with all action types, and (B) all users with one action type at a time. Performance metrics include ACC, AUC, FAR, FRR, and EER; ROC curves are shown in Figures 2–13. The paper reports per-user tables for each scenario and averages across the 10 listed users. There are some internal inconsistencies in the metric tables—e.g., Table 8 reports KNN FAR as 0.846 and EER as 0.847 for the PC action, which appears likely to be a typo because the surrounding narrative says KNN performs best on PC and the ACC/AUC are near-perfect. Likewise, the paper sometimes labels EER as ERR in text, suggesting editing issues.
Reproducibility: the implementation uses scikit-learn, which makes the baseline approach easy to reproduce in principle, but the paper does not release code, fixed splits, exact hyperparameters, or frozen processed datasets. Because the feature set is borrowed from prior work and the data source is a known benchmark, a partial reproduction is feasible, but the exact reported numbers are not independently checkable from the paper alone. The strongest reproducibility gap is the lack of per-user split specification and the absence of a clear protocol for choosing thresholds for FAR/FRR/EER.
Technical innovations
- A side-by-side empirical comparison of Decision Tree, KNN, and Random Forest on the Balabit mouse-dynamics benchmark under both verification and authentication formulations.
- A two-scenario evaluation design that separates single-user/all-actions testing from all-users/single-action testing, exposing which action type carries the most discriminative signal.
- Use of the standard 39-feature Balabit mouse-action representation across MM, PC, and DD to analyze continuous authentication performance without introducing a custom feature extractor.
Datasets
- Balabit Mouse Challenge dataset — 10 users (paper reports 10 evaluated users: 7, 9, 12, 15, 16, 20, 21, 23, 29, 35) — public benchmark, collected at Balabit company office; total sessions/action counts not reported in this paper
Baselines vs proposed
- Decision Tree (scenario A, single user all actions): ACC = 91.9% vs proposed context's best reported ACC = 99.3% (KNN in scenario B, PC action)
- K-Nearest Neighbors (scenario A, single user all actions): ACC = 94.4% vs proposed context's best reported ACC = 99.3% (scenario B, PC action)
- Random Forest (scenario A, single user all actions): ACC = 79.7% vs proposed context's best reported ACC = 89.9% (scenario B, PC action)
- Antal et al. 2018 baseline on Balabit: average ACC = 80.17%, AUC = 0.87 vs this paper's reported best average scenario B PC results: DT 87.6%/90.3%, KNN 99.3%/99.9%, RF 89.9%/92.5%
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2312.00802.
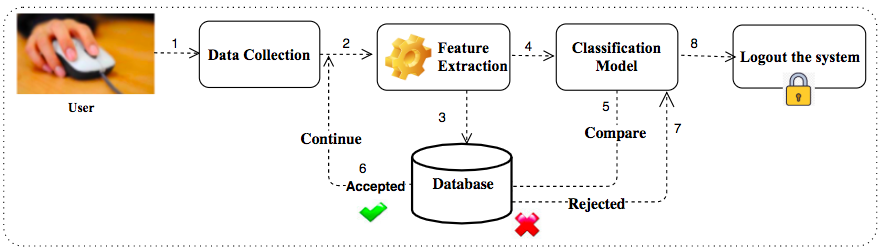
Fig 1: User Behavioral Biometrics Model
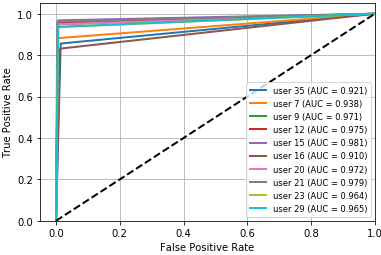
Fig 2: ROC curve for DT,
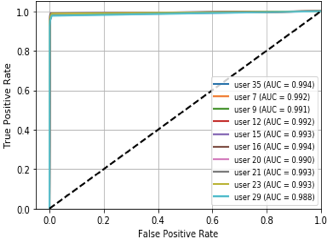
Fig 3: ROC curve for KNN,
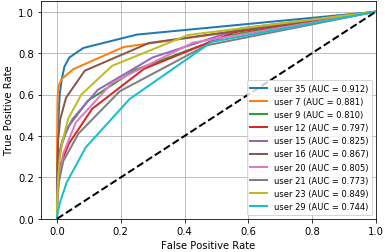
Fig 4: ROC curve for RF,
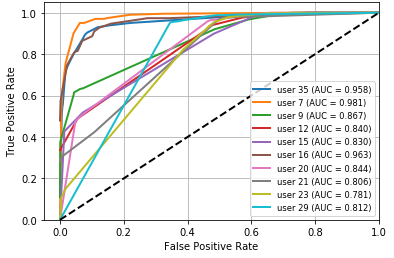
Fig 5: ROC curve for DT,
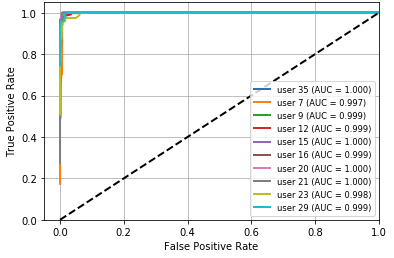
Fig 6: ROC curve for
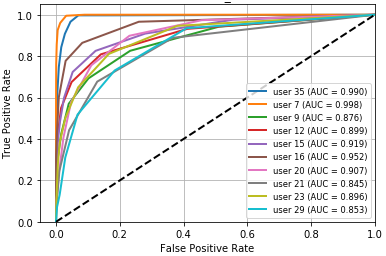
Fig 7: ROC curve for RF,
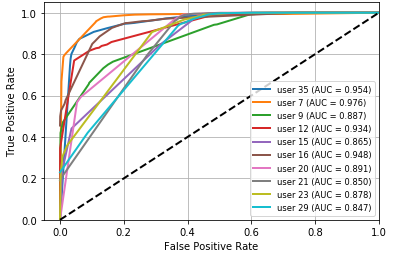
Fig 8: ROC curve for DT,
Limitations
- The paper does not report the total number of sessions, action instances, or class balance, so dataset scale and imbalance effects are hard to assess.
- Training uses a single 70/30 split with no repeated trials or cross-validation, so variance and split sensitivity are unknown.
- Classifier hyperparameters are not specified, especially important for KNN and Random Forest; results may depend heavily on defaults.
- The adversary model is simplistic: impostors are just other users in the dataset, with no adaptive attacker, mimicry, replay, or contamination analysis.
- Some tables appear to contain typographical or numerical inconsistencies (for example, KNN FAR/EER in Table 8 for PC action), which undermines confidence in exact values.
- There is no distribution-shift test across days, devices, or remote-session conditions, even though the dataset comes from remote desktop clients where context can matter.
Open questions / follow-ons
- Would the reported gains survive nested cross-validation with user-disjoint splits and tuned hyperparameters for each classifier?
- How robust are these features to cross-device and cross-context variation, such as different mouse hardware, remote desktop latency, or workstation posture changes?
- Can the same 39-feature representation support early detection with fewer actions, or does performance collapse when the window size is shortened?
- Would an adaptive impostor or imitation attacker significantly reduce the high ACC/AUC seen for KNN on point-and-click actions?
Why it matters for bot defense
For bot-defense practitioners, this paper is a reminder that simple behavioral telemetry can be highly discriminative when the task is narrowly scoped and the evaluation split is friendly. The strongest signal here comes from point-and-click actions, which suggests that high-level interaction primitives may be more useful than raw pointer traces for continuous risk scoring. In a CAPTCHA or step-up-authentication stack, these features could be treated as one weak signal among many rather than as a standalone authenticator, especially because the paper does not test adaptive attackers, cross-device drift, or long-horizon stability.
A bot-defense engineer would likely react by asking whether the classifier is distinguishing users or just dataset-specific session structure. The reported 100% verification accuracy and near-perfect KNN results on PC are promising but likely optimistic without stricter evaluation. The practical takeaway is to use mouse dynamics as one part of a layered policy: good for low-friction friction checks and anomaly scoring, not sufficient evidence by itself for high-assurance decisions.
Cite
@article{arxiv2312_00802,
title={ Continuous Authentication Using Mouse Clickstream Data Analysis },
author={ Sultan Almalki and Prosenjit Chatterjee and Kaushik Roy },
journal={arXiv preprint arXiv:2312.00802},
year={ 2023 },
url={https://arxiv.org/abs/2312.00802}
}