
A Survey of Adversarial CAPTCHAs on its History, Classification and Generation
Source: arXiv:2311.13233 · Published 2023-11-22 · By Zisheng Xu, Qiao Yan, F. Richard Yu, Victor C. M. Leung
TL;DR
This paper is a survey of adversarial CAPTCHAs, positioned as a response to the long-running security/usability trade-off in classic CAPTCHA design. The core problem it addresses is that increasingly capable OCR and deep-learning recognizers can solve many traditional CAPTCHAs, while further geometric distortion quickly harms human usability. The authors argue that adversarial examples provide a cleaner way to preserve human readability while confusing machine vision systems.
What is new here is not a new attack algorithm, but a re-definition and taxonomy: the paper broadens “adversarial CAPTCHA” beyond imperceptible perturbations to include any CAPTCHA-like input that fools machine learning systems, then classifies them into semantic and non-semantic adversarial CAPTCHAs. It also surveys image/text and audio generation methods, discusses defenses and limitations, and frames open research directions. As a survey, the main result is conceptual rather than empirical: it organizes a scattered literature and argues that adversarial CAPTCHAs should be evaluated as a security primitive against machine readers, not just as adversarial examples repurposed for CAPTCHA images.
Key findings
- Google’s 2014 distorted-text experiment is used as evidence that heavy distortion breaks the CAPTCHA premise: humans solved the most distorted texts at 33% accuracy, while the AI reached 99.8% accuracy.
- The authors explicitly extend the classic Terada et al. definition of adversarial CAPTCHA to include any technique that can fool machine learning models, not only imperceptible perturbations.
- Their taxonomy splits adversarial CAPTCHAs into semantic and non-semantic classes; semantic examples preserve human-readable content, while non-semantic ones remove semantic readability but remain machine-readable.
- For text-based CAPTCHAs, the survey argues that the perturbation magnitude must often be larger than for image-based CAPTCHAs because the semantic content is simpler and easier to disrupt.
- Among gradient-based attacks, FGSM is presented as a one-step fast method, I-FGSM as a multi-step refinement, PGD as a stronger randomized variant, and MI-FGSM as a momentum-based extension.
- The paper states that CW attack can be more than 100 seconds per example, whereas FGSM can take less than 0.1 seconds, highlighting the runtime gap between optimization-based and gradient-sign attacks.
- The survey notes that universal perturbations are attractive for CAPTCHA defense because a single perturbation can transfer across many inputs, unlike per-image attacks.
- It cites aCAPTCHA as a successful text-CAPTCHA method based on JSMA in the frequency domain (JSMA-f), but the provided excerpt does not include the dataset or quantitative benchmark details.
Threat model
The adversary is a bot or automated solver that uses OCR, deep neural networks, or other machine-learning classifiers to recognize CAPTCHA content; in some cases, the attacker may also have physical-world access and use stickers or patches to alter what a camera captures. The adversary is assumed to know the CAPTCHA format and can train or deploy recognition models. What they cannot do, in the intended CAPTCHA setting, is reliably solve the test as a human would without leveraging machine recognition; the defender wants a mechanism that preserves human readability while causing machine misclassification.
Methodology — deep read
This is a survey paper, so its methodology is literature synthesis rather than a controlled experimental pipeline. The threat model is stated implicitly: the defender operates a CAPTCHA system, while the adversary uses OCR or deep models to automatically solve it. The paper’s emphasis is that the attacker knows the CAPTCHA is machine-generated and can train or apply recognition models; the defender wants a test that is still readable to humans but unreliable for machines. The paper also distinguishes a separate, physical-world sticker/patched setting where an attacker can modify the captured scene rather than the image file itself.
Data-wise, the paper does not introduce a new dataset or benchmark suite. Instead, it reviews historical CAPTCHA systems and generation methods. The text names classic systems such as Gimpy, EZ-Gimpy, Gimpy-r, phpBB CAPTCHAs, reCAPTCHA v1/v2/v3, and Tencent MedCAPTCHA, and it references the classes of media involved: text, image, audio, drag-based, and video-based CAPTCHAs. For adversarial-example methods, the survey discusses standard image-classification benchmarks only at the conceptual level; in the excerpt provided, no training splits, sample counts, or preprocessing pipelines are reported because the paper is not re-running those attacks itself.
The central algorithmic contribution is the new formalization and taxonomy. The paper first restates the classic notion from Terada et al. as a CAPTCHA hardened by adversarial-example techniques, then broadens it to: any CAPTCHA that can fool machine-learning models through any model-fooling technique. Based on whether semantic information remains accessible to humans, it defines two families. Semantic adversarial CAPTCHAs preserve meaning for humans and include perturbation-based CAPTCHAs and sticker/patch-based CAPTCHAs. Non-semantic adversarial CAPTCHAs remove semantic readability for humans while remaining machine-decodable. Within the survey, the authors organize the attack-generation literature into categories: gradient-based (FGSM, I-FGSM, PGD, MI-FGSM, JSMA, DeepFool), optimization-based (L-BFGS, CW), universal perturbations, evolutionary methods (one-pixel attack), and generative methods (ATN, AdvGAN, AdvGAN++). For each family, the paper explains the core input/output mapping: e.g., FGSM computes one sign step on the loss gradient, CW optimizes a perturbation under an L0/L2/L∞ constraint, and AdvGAN trains a generator/discriminator pair to emit adversarial examples without querying the target loss at inference time.
Because this is a survey, there is no training regime in the usual sense for a new model. Where the paper discusses underlying methods, it summarizes their known properties rather than reproducing their hyperparameters: FGSM is single-step and fast, I-FGSM iterates with clipping to valid pixel ranges, PGD adds random initialization to improve the chance of reaching a stronger local maximum, and CW uses logits rather than softmax and a tanh reparameterization to keep pixels in range. The excerpt does not specify epochs, batch sizes, seed strategy, or hardware, and it does not claim new empirical training results of its own. The paper does, however, make an important practical point for CAPTCHA design: the perturbation budget for text CAPTCHAs can be larger than for image CAPTCHAs because text is simpler and more brittle, which changes the attack/defense optimization target.
Evaluation in the paper is literature-based: it compares attack families qualitatively by perturbation magnitude, generation speed, and the kind of perceptual effect they create. It highlights known comparison points from prior work, such as FGSM vs I-FGSM/PGD, CW’s stronger optimization at much higher runtime, and the transferability of universal perturbations. The survey also reviews defense ideas against adversarial CAPTCHAs and argues that the relevant metric is not just model accuracy but the gap between human solvability and machine solvability under attack. No formal statistical testing, cross-validation, or held-out attacker evaluation is reported in the excerpt, and the paper does not present a benchmark table of its own results; any figures referenced are descriptive, such as the timeline of CAPTCHA development and examples of specific schemes.
Reproducibility is limited by the genre and by the excerpted text. The paper appears to be a survey chapter/article with citations to prior work rather than a code-and-data release. The practical reproducibility value is in the taxonomy and bibliography, not in frozen weights or a released dataset. One concrete end-to-end example in the paper is the explanation of reCAPTCHA v1: a user receives two words, one known control word and one scanned unknown word; if the user correctly types the control word, the system infers the unknown word is also likely correct, and uses multiple user responses to disambiguate suspicious entries. This example is used to show how a CAPTCHA can double as an annotation pipeline and why machine recognition of the content undermines the scheme.
Technical innovations
- Extends the definition of adversarial CAPTCHA from imperceptible perturbation-based inputs to any CAPTCHA-like input that can fool machine-learning solvers.
- Introduces a semantic vs non-semantic taxonomy to separate human-readable adversarial CAPTCHAs from machine-readable but human-unrecognizable ones.
- Organizes adversarial-CAPTCHA generation methods by attack family: gradient-based, optimization-based, universal, evolutionary, and generative.
- Frames adversarial CAPTCHAs explicitly as a defender-side use of model-fooling techniques against attacker-side recognizers.
Baselines vs proposed
- Google distorted-text experiment: humans = 33% accuracy vs AI = 99.8% accuracy on the most distorted texts
- CW attack: generation time >100 seconds/example vs FGSM: <0.1 seconds/example
- No unified benchmark table is reported in the provided text excerpt for the survey’s own taxonomy or categories
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2311.13233.
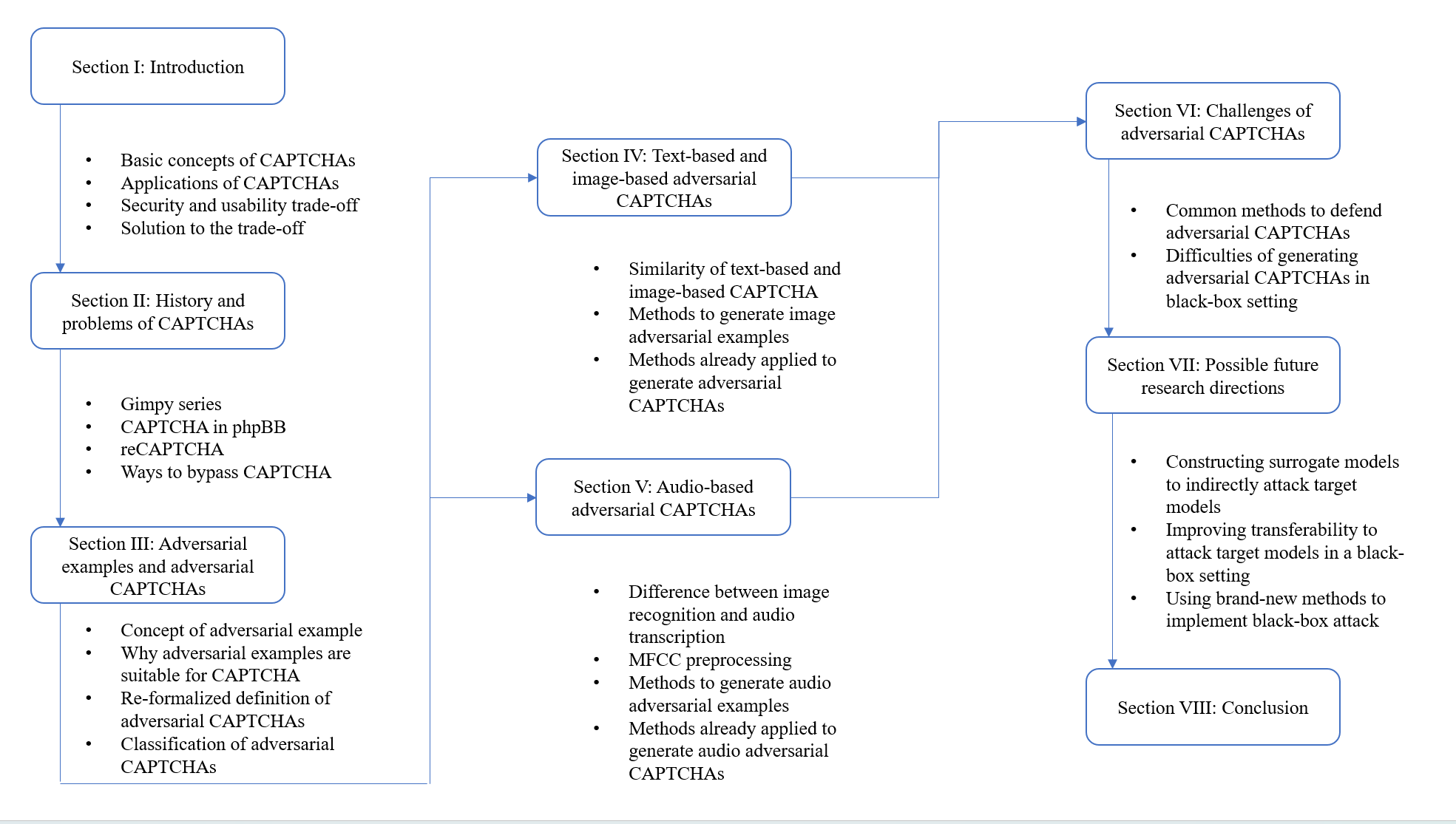
Fig 1: Overall structure of this paper
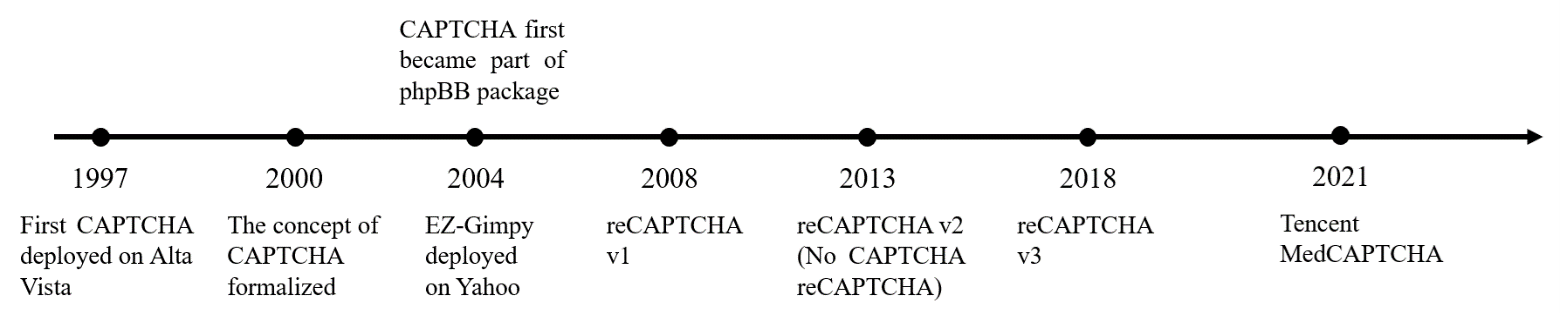
Fig 2: Timeline of CAPTCHA development

Fig 3: Examples of Gimpy, EZ-Gimpy, and Gimpy-r
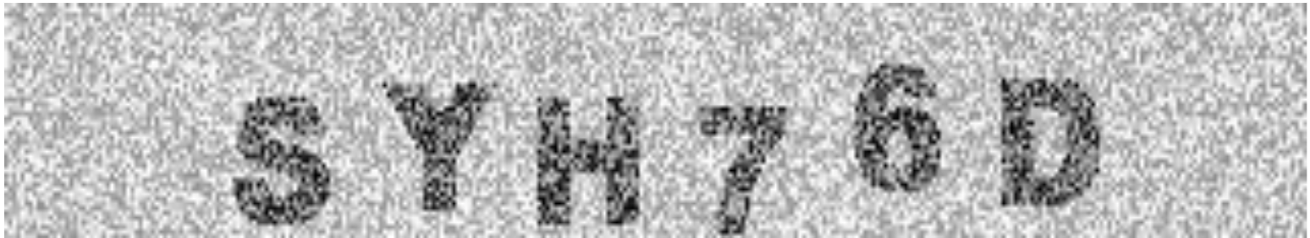
Fig 4: (a) The original version of CAPTCHA used in phpBB. (b) The new version of CAPTCHA used in phpBB.

Fig 5: (a) Example of reCAPTCHA v1. (b) “I’m not a robot” checkbox. (c) The secondary check was presented

Fig 6: Adversarial example generated by FGSM by Goodfellow et al. [29]
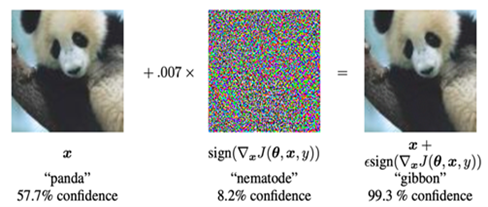
Fig 7: presents our way to categorize adversarial CAPTCHAs. Traditionally, adversarial
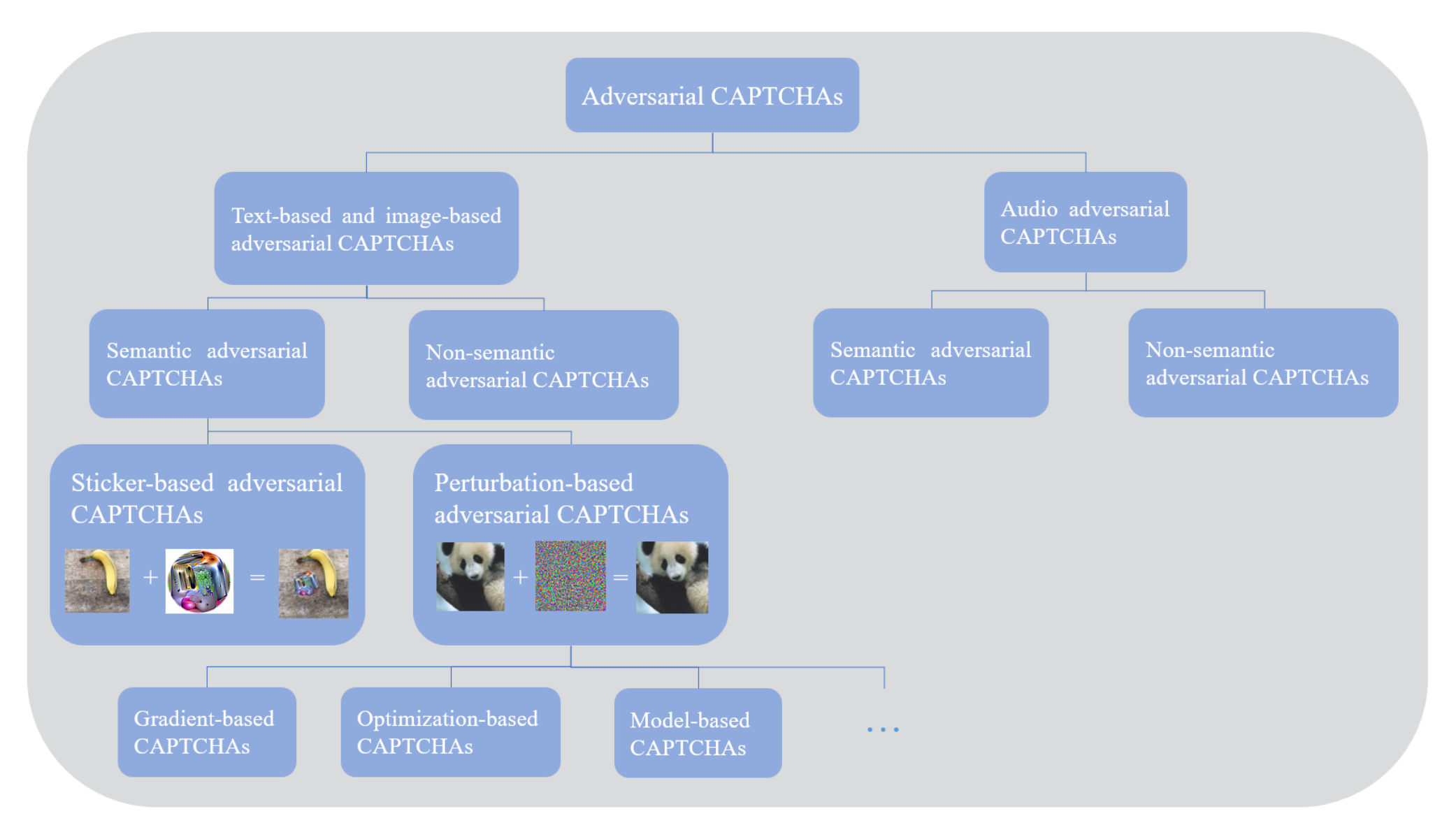
Fig 8 (page 9).
Limitations
- This is a survey, so it does not provide new benchmarked results, ablations, or a standardized evaluation protocol.
- The excerpt does not specify a literature search method, inclusion/exclusion criteria, or coverage completeness, so the survey process is not fully auditable from the text provided.
- Many cited attack methods are described qualitatively; the paper often omits exact datasets, hyperparameters, and attack budgets for the underlying papers.
- The broad re-definition of adversarial CAPTCHA is conceptually useful, but it may blur boundaries between CAPTCHA design, adversarial examples, and physical-world adversarial patches.
- Defense discussion is high-level in the excerpt; it does not give a rigorous comparative evaluation of defenses against adaptive attackers.
- No user-study data is presented here to quantify the human usability impact of the proposed taxonomy categories.
Open questions / follow-ons
- How should adversarial CAPTCHAs be evaluated under adaptive attackers who retrain on the CAPTCHA distribution itself?
- Can a standardized benchmark be built that jointly measures human solve rate, machine solve rate, latency, and attack transferability across text, image, audio, and video CAPTCHAs?
- What is the right security/usability frontier for semantic vs non-semantic adversarial CAPTCHAs under accessibility constraints?
- How robust are these schemes to preprocessing defenses, OCR ensembles, and multimodal solver pipelines?
Why it matters for bot defense
For a bot-defense engineer, the main takeaway is that “make it more distorted” is no longer a stable strategy. If a solver can be trained on your CAPTCHA distribution, then geometric distortion alone may only erode human usability while leaving the machine advantage intact. The survey’s taxonomy is useful operationally because it separates schemes that preserve semantic content from those that do not, which maps directly to whether a CAPTCHA can still be answered by a human without external assistance.
In practice, this paper is most useful as a design-and-threat-model checklist. It suggests that any CAPTCHA relying on visible structure should be tested against modern recognizers, not just classical OCR, and that defenses need to account for adaptive retraining, transferability, and possibly physical-world patch attacks. It also hints that nonvisual or interaction-based signals may be preferable in some settings, because once semantic text/image content is machine-solvable at scale, the remaining room for adversarial-image tricks is narrow.
Cite
@article{arxiv2311_13233,
title={ A Survey of Adversarial CAPTCHAs on its History, Classification and Generation },
author={ Zisheng Xu and Qiao Yan and F. Richard Yu and Victor C. M. Leung },
journal={arXiv preprint arXiv:2311.13233},
year={ 2023 },
url={https://arxiv.org/abs/2311.13233}
}