
UA-Radar: Exploring the Impact of User Agents on the Web
Source: arXiv:2311.10420 · Published 2023-11-17 · By Jean Luc Intumwayase, Imane Fouad, Pierre Laperdrix, Romain Rouvoy
TL;DR
UA-Radar studies whether the User-Agent string still materially changes what modern websites serve, or whether it is mostly legacy noise that can be removed without breaking the web. The authors build a measurement pipeline that compares pages along five axes: DOM structure, HTML text, JavaScript, CSS, and screenshot-level visual rendering. A key methodological choice is to separate static differential serving from dynamic, script-driven adaptation by crawling each page twice with a standard browser and twice with a “None” UA variant, then diffing the within-UA crawls to strip out time-varying content before comparing standard vs. None.
The main result is strikingly negative for server-side UA negotiation: across 270,048 page crawls from 11,252 domains, they report 100% similarity before any JavaScript execution for Chromium, Firefox, and WebKit, implying no observed differential serving in the sampled web. After JavaScript runs, 8.4% of domains (955/11,252) show UA-dependent changes, but these are attributed mostly to third-party scripts and client-side adaptation rather than origin servers. The paper’s practical conclusion is that, for most sites in this crawl, browsers could reduce or freeze UA without visible breakage, while the small set of affected sites is often fixable by making code browser-agnostic.
Key findings
- 270,048 crawled page instances from 11,252 domains were successfully collected over 1 month, with 5,848 GB of compressed data retained; JavaScript dominated storage at 4,705 GB (73,573,872 files), versus 959 GB CSS and 17 GB HTML.
- Before JavaScript execution, average similarity was 100% for Chromium vs Chromium-None (CCN), Firefox vs Firefox-None (FFN), and WebKit vs WebKit-None (WWN) across HTML structure, HTML content, JavaScript, and CSS.
- The authors found 955/11,252 domains (8.4%) with UA-dependent changes after JavaScript execution; 158/11,252 had at least one visual-rendering difference, and every visually different site also differed in HTML structure and HTML content.
- Among the UA-dependent domains, 526 were labeled SEVERE, 67 UNUSABLE, 225 IRRITANT, 131 MODERATE, and 6 NO PATTERN using the authors’ heuristic severity taxonomy.
- News sites were the most affected category among UA-dependent domains (180 domains), followed by Internet Services (156), Business (128), Online Shopping (109), and Marketing (106).
- The paper reports that UA-dependent changes were often driven by third-party scripts from ads, bot detection, and CDN services, rather than by first-party server-side content negotiation.
- For the top categories, Internet Services, Business, and Marketing were near-100% similar across all dimensions, while News and Online Shopping had noticeably lower HTML-content and visual-rendering similarity; WebKit often scored best except in Online Shopping, where its HTML-content similarity dropped toward Firefox levels.
Threat model
The relevant adversary is not a malicious attacker but a modern web server or script stack that may adapt content based on browser-identifying information, intentionally or unintentionally. The browser-side capability under study is the ability to hide or neutralize UA-identifying fields in the HTTP request and Navigator object; the paper assumes the server can observe those fields but does not assume any exotic active probing beyond normal web delivery and client-side execution. The authors do not model an attacker who can defeat the measurement harness or a browser-specific exploit; instead, they ask whether removing UA information breaks sites in normal browsing conditions.
Methodology — deep read
The threat model is not a classic attacker model but an impact-assessment model for browser-side UA reduction. The authors assume modern browsers can hide or replace UA-identifying fields (HTTP User-Agent plus navigator.appVersion, navigator.platform, navigator.userAgent, navigator.vendor) with the string “None,” and they explicitly set navigator.webdriver=false to avoid bot-triggered rejection during measurement. What they are measuring is whether the web still needs that identifying information for content delivery and rendering. The comparison is browser-pair based: standard browser versus its “None” counterpart, for Chromium, Firefox, and WebKit.
Data collection is a large-scale crawl of homepage URLs from the Tranco list. They randomized the crawl order and ultimately kept 12,000 domains planned, but only 11,252 domains were fully successful after enforcing a strict completeness rule: if all 24 requests for a domain were not successfully crawled and saved, the entire domain was discarded. The crawl lasted one month and produced 270,048 saved web pages. For each domain they performed four visits per browser: two visits before JavaScript execution to study differential serving, and two visits after JavaScript execution to study content adaptation. With six browser variants total (Chromium, Firefox, WebKit, and their None versions), this yields 24 visits per homepage. Pre-JS captures were taken at domcontentloaded and post-JS captures at 15 seconds after load. The retained artifacts included HTML, JS, CSS, and screenshots; the paper reports 100,994,056 total files and 5.85 TB compressed disk usage. One concrete example: a site is crawled twice with Chromium and twice with Chromium-None before JS; the two Chromium crawls are diffed to isolate dynamic content, the two Chromium-None crawls are diffed similarly, and the resulting static backbones are compared to estimate whether removing UA information changes the page.
UA-Radar itself is a multi-dimensional similarity framework. For HTML structure, they extract DOM trees and compare them with SFTM, a tree-matching tool that produces a graph of edit operations; similarity is computed as |C|/|E|, where C is the number of edit operations and E the number of edges. For HTML content, they use Diff Match Patch (Myers diff / Levenshtein-style distance) on raw text content, again normalizing by the graph size to get a similarity score. For JavaScript and CSS, they first hash file contents with LSH to identify changed files, then parse them into ASTs and compare them with GumTree; similarity is |D|/|E|, where D is the number of edit operations. For visual rendering, they propose a contour-based method: screenshots are converted to grayscale, contours are extracted with OpenCV/Canny-style processing, and the method computes three properties—number of contours, weighted contour areas, and weighted contour moments. These are combined via a geometric mean GM = cbrt(|C| × A × M), and visual similarity is defined as the relative difference |GM1 − GM2| / ((GM1 + GM2)/2). The visual method is intended to capture meaningful layout/content changes such as missing text, images, or broken sections rather than tiny pixel noise.
Evaluation is primarily descriptive and regression-style rather than predictive. For each browser pair (CCN, FFN, WWN), they report average similarity before JS and after JS, and they break down results by website category using McAfee SmartFilter categories for the UA-dependent set. They also manually inspect 204 of the 955 UA-dependent domains to identify 10 recurring change patterns, then use heuristics derived from those patterns to classify the rest of the affected set into Rubin-style usability severities. The heuristic inspects differences across standard-vs-None comparisons and checks for specific CSS/HTML cues such as margin-top/bottom, white-space: wrap, page-break-before/after, image src changes, iframe width/height changes, disabled/inactive tags, CAPTCHA presence, and HTTP 403 responses. They additionally compare standard browser pairwise diffs (Chromium vs Firefox, Chromium vs WebKit, Firefox vs WebKit) to decide whether a UA-driven change is actually distinct from normal browser variation. The paper does not report statistical significance tests, confidence intervals, or cross-validation. It also does not present released code or frozen model weights because this is not a learned model paper; it does say the dataset repository is available in the paper’s artifacts section.
The paper is careful about a concrete browser-compatibility example: in a severe case shown in Fig. 5, the None browser fails margin collapse, leading to a visible rendering break. The authors use this kind of manually identified pattern to populate the heuristic severity classifier. However, the exact implementation details of some parts are underspecified: the formula naming is a bit inconsistent (for example, the HTML-content similarity description is not as formally clear as the tree and contour sections), and the paper does not provide a full, line-by-line implementation of the heuristic classifier in the excerpt shown. Likewise, although they mention a one-month crawl on Playwright, they do not give hardware specs, CPU/GPU details, batch-size analogues (not applicable here), or random seed strategy.
Technical innovations
- UA-Radar combines structural, textual, AST, and screenshot-contour similarity into one multi-axis radar rather than relying on a single HTML or visual comparison metric.
- The crawl design explicitly separates differential serving from JavaScript-driven adaptation by using within-UA double crawls to extract a static backbone before comparing standard vs None pages.
- The paper introduces a contour-based screenshot comparison using contour count, weighted area, and moments, summarized by a geometric-mean score instead of pixel-wise or perceptual hashing alone.
- It derives a heuristic severity classifier for UA-dependent breakage from manually observed patterns and maps them to Rubin-style usability severity labels.
Datasets
- Tranco homepages crawl — 11,252 domains / 270,048 page instances — Tranco list
- Crawl artifacts — 100,994,056 files, 5,848 GB compressed — authored crawl repository/artifacts
Baselines vs proposed
- Standard browser vs None browser (pre-JS): similarity = 100% across HTML structure, HTML content, JavaScript, and CSS for CCN/FFN/WWN vs proposed: 100%
- Standard browser vs None browser (post-JS): 955/11,252 domains UA-dependent vs proposed: 8.4% of domains affected
- Visual rendering differences: 158/11,252 domains not 100% visually similar for at least one browser pair vs proposed: 158 domains
- UA-dependent domains severity: IRRITANT=225, MODERATE=131, NO PATTERN=6, SEVERE=526, UNUSABLE=67 vs proposed: heuristic classification output
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2311.10420.
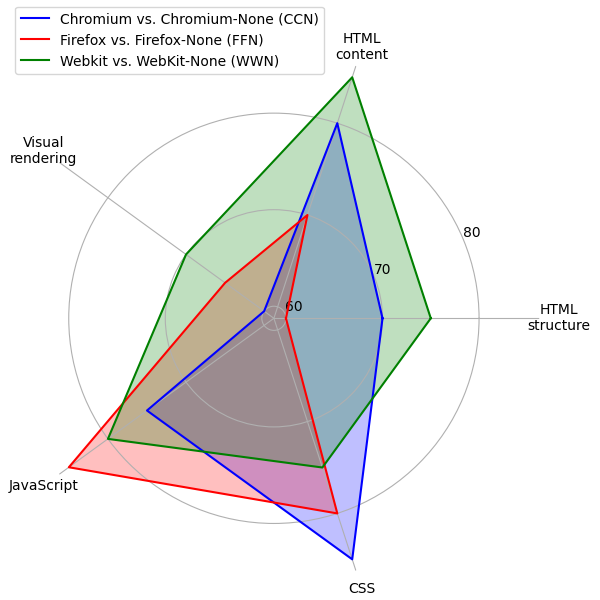
Fig 1: Similarity radar for a web page: the above

Fig 2: Highlighting web page similarity: standard browser (𝑈𝐴) versus None-browser (𝑈𝐴′). We crawl each web page twice

Fig 3: Contour-based visual analysis: the figure

Fig 4 (page 4).

Fig 5 (page 4).
Fig 4: Average similarity scores across website categories: this figure illustrates the average similarity scores between

Fig 7 (page 5).
Fig 5: Comparison of web page rendering with standard and none browsers, illustrating a ’severe’ problem severity case
Limitations
- The crawl covers only homepages, so internal pages, logged-in states, checkout flows, and other deep-site behaviors are not evaluated.
- The study uses a Tranco-based popularity sample, which may not represent the long tail or regional/site-specific ecosystems.
- The severity labeling is based on manual inspection of 204 domains and heuristics extrapolated to the rest; that leaves room for subjective bias and misclassification.
- No statistical significance testing or confidence intervals are reported in the excerpt, so the stability of the measured 8.4% figure is not quantified.
- The paper observes UA-dependent changes after JavaScript, but it cannot always cleanly attribute them to first-party logic versus third-party scripts or runtime environment quirks.
- The visual-similarity method is novel but heuristic; it may miss subtle functional regressions or overstate differences caused by benign layout shifts.
Open questions / follow-ons
- Which specific third-party script providers account for most UA-dependent breakage, and how much of it is due to bot-detection rather than genuine browser-compatibility logic?
- Would the 8.4% UA-dependent rate persist on authenticated pages, mobile layouts, or non-homepage flows such as search results and shopping carts?
- How do UA-reduction strategies compare with Client Hints in practice: does migration preserve compatibility while reducing fingerprinting risk, or merely shift the dependency surface?
- Can the contour-based visual metric be calibrated against human judgments or task-level failures to better distinguish cosmetic differences from true usability regressions?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, the paper is useful because it shows that a non-trivial fraction of UA-sensitive breakage is driven by scripts in the same ecosystem that often hosts bot defenses, ads, and CDN logic. That means UA reduction can expose brittle assumptions in challenge delivery, script gating, or anti-automation middleware that keys off browser identity more than page state. If you operate a CAPTCHA or risk engine, this is a reminder to test against browser-agnostic clients and reduced-identification modes rather than relying on UA string checks as a compatibility or trust signal.
Practically, the study suggests a measurement pattern you can reuse: run paired crawls with standard and identity-reduced browsers, strip dynamic content by self-diffing repeated visits, then compare structural and rendered outputs. For CAPTCHA systems, that kind of analysis can reveal whether a challenge flow is failing because of genuine anti-bot checks, overbroad browser fingerprint gating, or third-party dependencies that assume a specific UA. The paper does not evaluate CAPTCHA bypass directly, but it does show that hiding UA alone does not generally change the static page, so any CAPTCHA behavior that hinges on UA is a compatibility risk and a weak security primitive.
Cite
@article{arxiv2311_10420,
title={ UA-Radar: Exploring the Impact of User Agents on the Web },
author={ Jean Luc Intumwayase and Imane Fouad and Pierre Laperdrix and Romain Rouvoy },
journal={arXiv preprint arXiv:2311.10420},
year={ 2023 },
url={https://arxiv.org/abs/2311.10420}
}