
A bot detection ml model is a scoring system that separates likely humans from likely automation using behavioral, device, and network signals. The best ones do not try to “prove” a user is human; they estimate risk well enough to protect the flow without punishing real users.
That framing matters because bot traffic is rarely one thing. You may see credential stuffing, ticket scalping, account creation abuse, scraping, or simple high-volume form spam. A model that works for one abuse pattern can fail badly on another, so the goal is usually layered detection: model scores plus rules, rate limits, and challenge orchestration.
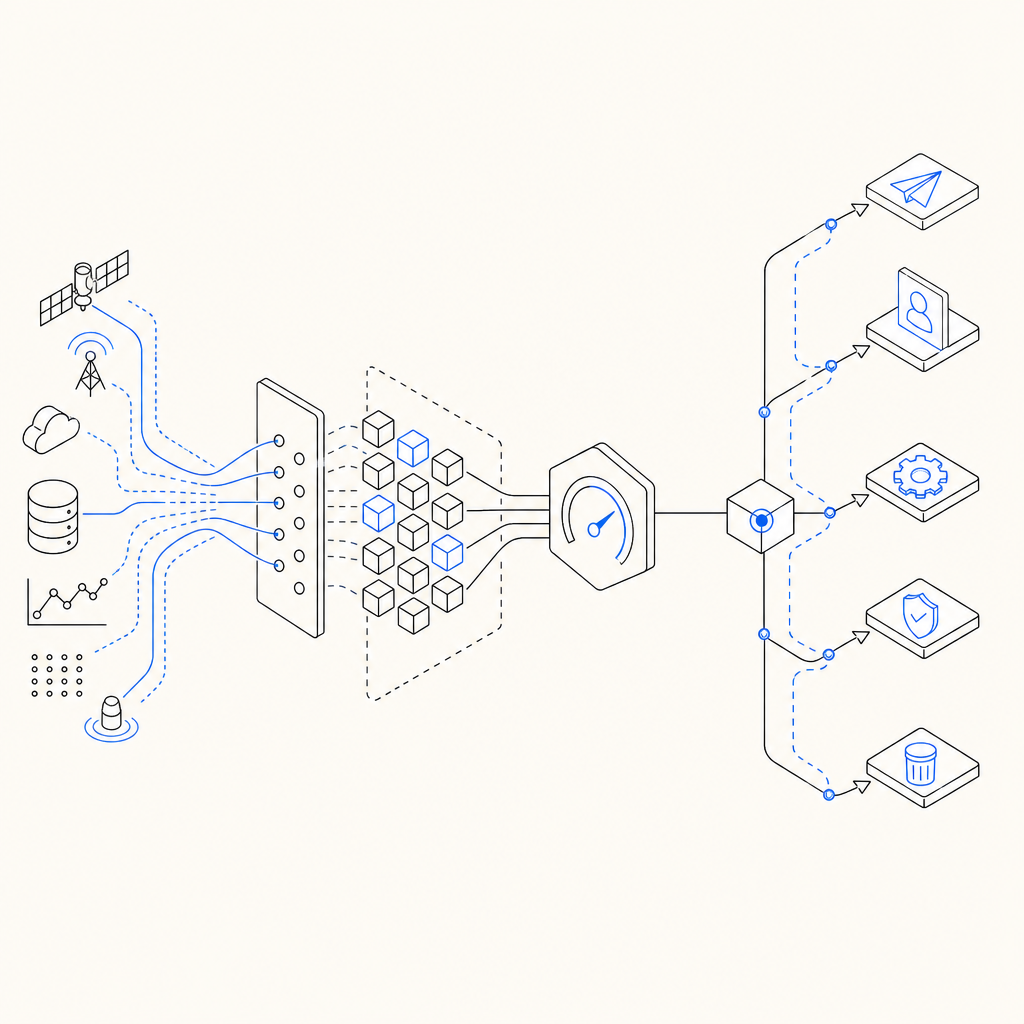
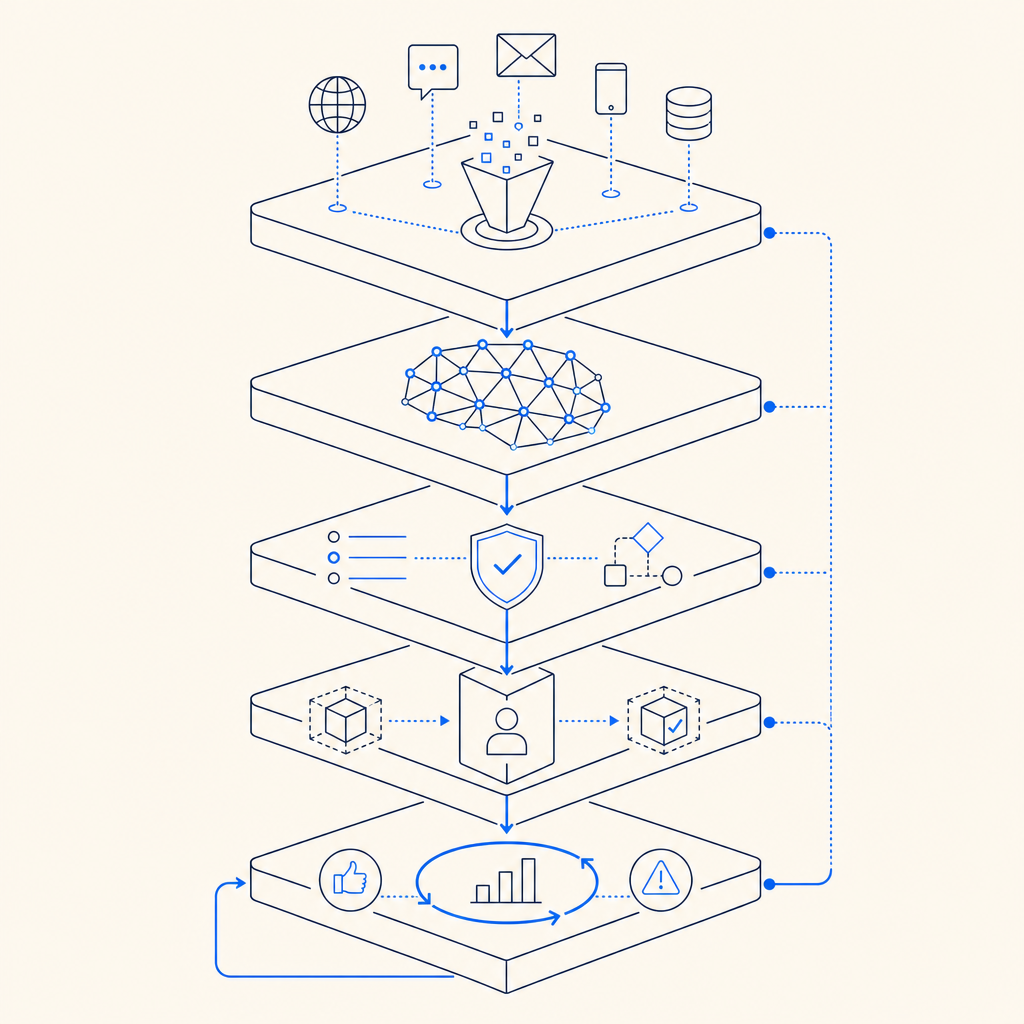
A practical bot detector has three jobs: collect signals, turn them into features, and produce an action. The action might be allow, step-up challenge, or block. If you are building this yourself, the hardest part is not the algorithm; it is keeping labels clean, drift controlled, and false positives low enough that support does not fill up with angry users.
What a useful bot detection ML model actually learns
A strong bot detection model learns patterns that are hard to fake consistently across a session. It does not rely on a single “bot-like” trait, because those get noisy fast. Instead, it combines signals that are individually weak but collectively meaningful.
Common input groups include:
Behavioral signals
- Inter-event timing
- Mouse movement entropy
- Scroll cadence
- Typing speed and hesitation
- Focus/blur patterns
Browser and device signals
- User agent consistency
- Canvas/WebGL characteristics
- Timezone and locale mismatch
- Headless browser hints
- SDK integrity or tamper evidence
Network and session signals
- IP reputation
- ASN, geo, and proxy indicators
- Request burst patterns
- Cookie persistence
- Token reuse across sessions
Contextual signals
- Endpoint sensitivity
- Account age
- Historical risk for the same entity
- Velocity across multiple actions
A useful mental model is that the model predicts abuse probability, not “botness” in the abstract. That gives you room to tune thresholds per route. A login endpoint and a newsletter signup should rarely share the same threshold.
Data quality matters more than model choice
Teams often start by debating XGBoost versus neural nets versus logistic regression. That is usually the wrong first debate. In bot defense, the label pipeline determines whether the model becomes a useful signal or a noisy liability.
Label sources that usually work
- Manual review on sampled traffic
- Confirmed abuse after downstream investigation
- Challenge outcomes, used carefully
- Account bans tied to evidence
- Known-good traffic from employees or test cohorts
Common data traps
- Using challenge failures as a pure bot label without accounting for accessibility issues
- Training on yesterday’s blocked traffic only
- Letting one bad rule create circular labels
- Mixing environments, such as staging and production, without separation
- Overweighting rare attack bursts and underweighting normal daily variation
If you want a model that survives production, you need a feedback loop. Predictions should feed monitoring, and monitored outcomes should update the training set. Otherwise the system slowly learns yesterday’s attack script and forgets how real users behave.
For teams that do not want to build every layer from scratch, CaptchaLa provides challenge delivery and validation plumbing so you can spend more effort on policy and signal design than on glue code. Its setup is oriented around first-party data only, which is a useful constraint if privacy and compliance are part of your architecture.
A practical architecture for scoring and enforcement
A bot detection ml model should not be the only gate. The cleanest production pattern is usually:
- Collect signals at the client and server edges.
- Compute a risk score close to the request.
- Combine score with deterministic rules.
- Choose a response:
- allow
- step up with a challenge
- rate limit
- deny
- Log outcomes for retraining and audits
A minimal scoring service might look like this:
# English comments only
def risk_score(features):
score = 0.0
if features["request_rate_60s"] > 20:
score += 0.35
if features["mouse_entropy"] < 0.2:
score += 0.20
if features["ip_reputation"] == "bad":
score += 0.30
if features["cookie_age_days"] < 1:
score += 0.10
if features["headless_hint"]:
score += 0.25
return min(score, 1.0)
def decide(score):
if score >= 0.80:
return "block"
if score >= 0.50:
return "challenge"
return "allow"That code is intentionally simple, but the pattern is real: a model score plus policy thresholds. In practice, many teams use a hybrid approach where the ML model feeds a risk score and deterministic rules catch sharp edges like known-bad IPs or impossible velocity.
Model evaluation metrics that matter
Accuracy alone is not enough. In bot defense, false positives are expensive and class imbalance is extreme. Better metrics include:
- Precision at high recall
- False positive rate on trusted traffic
- Detection rate by attack type
- Challenge pass rate by cohort
- Latency added per request
- Stability under seasonal traffic shifts
If you cannot measure performance by endpoint, geography, and device class, you are probably hiding a problem. A single global score can look great while silently harming one browser family or one region.
How commercial CAPTCHA systems fit into the model
A lot of teams eventually realize they do not need to reinvent every piece. A CAPTCHA or challenge system can become part of the feature set, the policy engine, or both. That is where products like reCAPTCHA, hCaptcha, Cloudflare Turnstile, and CaptchaLa usually enter the picture.
The difference is less about “which one is magical” and more about what you can operationalize cleanly.
| Product | Typical strength | Notes |
|---|---|---|
| reCAPTCHA | Broad familiarity and ecosystem support | Often used as a default challenge layer |
| hCaptcha | Flexible challenge model and anti-abuse focus | Common where challenge tuning matters |
| Cloudflare Turnstile | Low-friction verification | Popular for reducing user friction |
| CaptchaLa | Integration-friendly validation and SDK coverage | Useful when you want first-party flow control |
CaptchaLa supports eight UI languages and native SDKs for Web (JS/Vue/React), iOS, Android, Flutter, and Electron, which makes it easier to keep the experience consistent across apps. On the server side, it offers SDKs for captchala-php and captchala-go, and validation can be done with a straightforward POST to https://apiv1.captcha.la/v1/validate using pass_token and client_ip with X-App-Key and X-App-Secret. If you need server-issued tokens, the issue endpoint is POST https://apiv1.captcha.la/v1/server/challenge/issue.
For teams that want to wire this into their own model, the usual pattern is: let the model decide whether to challenge, then validate the result server-side, then feed that outcome back into training. docs is the place to check the exact request shapes and SDK details.
Deployment details that keep models useful
The last mile is where good bot detection systems often fail. A model that is decent in offline evaluation can still create pain if it is too slow, too brittle, or too hard to update.
A few deployment rules help a lot:
Keep inference close to the decision point
If the model sits too far from the request, latency and timeout handling become your real bottleneck.Version features, not just models
Feature drift is subtle. If a feature changes meaning, your model may degrade even though the file version looks fresh.Start with conservative thresholds
Put users first. You can always tighten policy once the confidence is there.Track per-route metrics
Login, signup, password reset, checkout, and search should never be treated as identical surfaces.Preserve an audit trail
When a user is challenged or blocked, you want to know why. That helps support, security, and retraining.
A simple rollout strategy is to shadow-score first, then challenge a small fraction of traffic, then expand. That lets you see whether the model behaves as expected without putting the whole funnel at risk.
If you are just getting started, a free tier can be enough to test the plumbing before you commit to production volume. CaptchaLa’s pricing includes a 1000/month free tier, Pro tiers around 50K-200K, and Business at 1M, which gives teams room to move from prototypes to real traffic without changing their architecture every week. See pricing for current plan details.
Where to go next: if you are designing a bot detection ml model, start with the docs and your highest-risk endpoint first. docs will help you wire validation correctly, and pricing is the quickest way to estimate what a rollout would look like for your traffic.