
Anti-scraping laws are the rules that can make unauthorized scraping illegal, risky, or contractually prohibited depending on the country, the site terms, and how the data is accessed. The short answer is: yes, they matter a lot, but they are not a single global law. What counts as scraping, what is protected, and what enforcement looks like varies by jurisdiction and by the technical details of the collection method.
For businesses, the real question is less “Is scraping always illegal?” and more “What access patterns should we allow, rate-limit, log, challenge, or deny to reduce legal and operational risk?” That framing matters because your defenses should be aimed at abuse prevention, not at blocking legitimate users or creating accidental barriers to accessibility.
What anti-scraping laws actually cover
Anti-scraping laws are usually part of a larger mix of contract law, computer misuse laws, anti-circumvention rules, privacy rules, and platform terms. They do not always say “scraping” explicitly. Instead, they may address:
- Unauthorized access to a computer system.
- Circumventing technical access controls.
- Breaching terms of service or contractual restrictions.
- Copying protected content at scale.
- Collecting personal data without a valid legal basis.
That mix is why two scraping cases with similar behavior can have very different outcomes. A request pattern that is tolerable for public indexing may become a problem when it ignores authentication boundaries, bypasses rate limits, or extracts data behind a login wall.
A practical way to think about risk
A useful mental model is to separate the data source into three buckets:
- Public, low-sensitivity content: lower legal risk, but still subject to terms and rate limits.
- Public but protected content: more risk if the site uses technical barriers or explicit restrictions.
- Authenticated, user-specific, or personal data: highest risk, especially if automation bypasses controls or harvests personal information.
If you run a site, you want controls that align with those buckets. If a resource is public but sensitive to abuse, use traffic shaping, anomaly detection, and friction only when behavior looks non-human or high volume. If a resource is authenticated, add stronger checks and audit trails.
The legal landscape: why jurisdiction matters
The biggest mistake teams make is assuming one country’s standard applies everywhere. It rarely does. Anti-scraping rules are shaped by region, court decisions, and the exact facts of the case.
United States
In the U.S., scraping disputes often turn on access authorization, contract breach, and whether someone bypassed technical barriers. Public web pages are not automatically free-for-all territory if the site has clear restrictions, login controls, or technical access measures. But the legal line can shift depending on what was accessed, how it was accessed, and whether any protections were circumvented.
European Union and UK
In the EU and UK, data protection and database-related rights can matter alongside contract and computer misuse rules. Personal data collection is especially sensitive under privacy law. Even if content is publicly reachable, repeated automated extraction may raise issues if it processes personal data without a lawful basis or ignores purpose limitations.
Other regions
Many countries are tightening cybercrime, privacy, and digital market rules. That makes a “scrape first, ask later” approach increasingly risky. For enterprises, the safest policy is to assume that unaudited automation on externally facing systems can create legal exposure unless there is a clear permission, agreement, or public API arrangement.
What businesses should do about scraping risk
The goal is not to eliminate all automation. The goal is to distinguish legitimate traffic from abuse and to document the controls you use. That helps with operations, incident response, and compliance.
A solid baseline includes:
- Publish clear terms that describe automated access, rate limits, and prohibited behavior.
- Expose a documented API for partners and approved integrations.
- Log suspicious patterns, including request rate, headers, IP reputation, and session behavior.
- Protect sensitive workflows with adaptive challenges rather than static blocks.
- Review whether collected data includes personal data, confidential data, or regulated records.
- Keep retention and access controls tight for logs that might expose user information.
Where this gets technical, bot-defense products help enforce policy without turning every page into a dead end. Tools such as CaptchaLa can be used as part of an adaptive access layer, especially when you need to challenge suspicious flows while keeping normal users moving. The same idea applies whether you prefer reCAPTCHA, hCaptcha, or Cloudflare Turnstile: the choice is less about brand and more about fit, privacy posture, and integration needs.
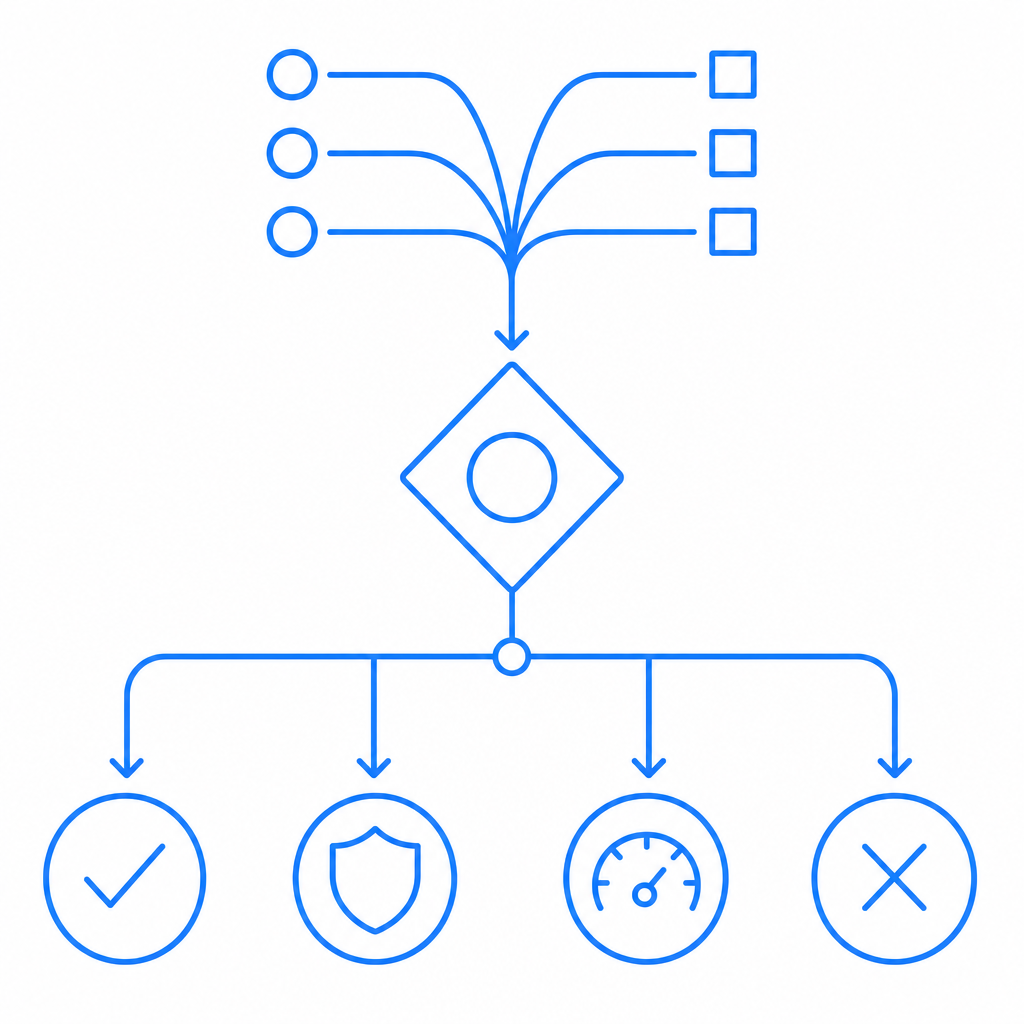
Designing defenses that help compliance instead of hurting UX
A common failure mode is using a single blunt control everywhere. That frustrates users and often still misses sophisticated automation. A better design uses layered signals.
Signals worth combining
- IP and ASN reputation
- Session stability over time
- Request velocity and burst patterns
- Cookie continuity
- Header consistency
- Mouse, touch, or navigation anomalies
- Login and checkout sensitivity
- Geographic and time-of-day anomalies
When multiple signals align, challenge the request. When the signal is ambiguous, use lighter friction. When the risk is clear, rate-limit or deny. This is one reason modern systems increasingly rely on server-side validation rather than only front-end checks.
A simple flow might look like this:
# English comments only
# 1. Receive request
# 2. Score behavior using traffic and session signals
# 3. If risk is low, allow normally
# 4. If risk is medium, issue a challenge
# 5. Validate token on the server
# 6. If risk is high or token fails, block or throttleThat server-side step matters because you want a trustworthy decision point. For example, CaptchaLa’s server validation is designed around a POST to https://apiv1.captcha.la/v1/validate with pass_token and client_ip, authenticated with X-App-Key and X-App-Secret. That kind of flow keeps the trust decision on your backend rather than in the browser alone. CaptchaLa also offers a server-token issuance endpoint at POST https://apiv1.captcha.la/v1/server/challenge/issue, which can be useful when your application needs to trigger challenges from the server side.
If you are implementing across multiple stacks, integration coverage matters. CaptchaLa supports Web via JS, Vue, and React, plus native SDKs for iOS, Android, Flutter, and Electron. Server-side support includes captchala-php and captchala-go. It also ships in 8 UI languages, which helps when challenges are part of a global product experience.
Comparing common bot-defense approaches
Different products emphasize different tradeoffs, and those tradeoffs matter for compliance and operations.
| Approach | Strengths | Tradeoffs |
|---|---|---|
| reCAPTCHA | Familiar, widely recognized | UX can be inconsistent; privacy review may be needed |
| hCaptcha | Strong focus on abuse prevention | May still require tuning for UX and false positives |
| Cloudflare Turnstile | Low-friction user experience | Best fit depends on existing edge/security stack |
| CaptchaLa | Flexible challenge flow, first-party data only, server validation | Requires thoughtful integration like any control |
The most important point is not which name is on the badge. It is whether your implementation gives you enough control over challenge timing, server validation, logging, and policy alignment.
How to document your anti-scraping posture
If legal, security, and product teams are aligned, documenting your posture becomes much easier. A concise policy can cover:
- Which endpoints are public, protected, or partner-only
- Whether automated access is allowed and under what conditions
- What rate limits apply
- Which signals trigger challenges
- How tokens are validated
- What data is stored, for how long, and why
That documentation is useful internally and externally. It helps support teams answer customer questions. It helps engineers avoid adding fragile exceptions. And if you ever need to explain why a scraper was blocked, you have a defensible trail.
For teams building or revisiting this stack, the docs are a useful place to review implementation details, and the pricing page can help size a deployment from free-tier experimentation to larger-volume use cases.
The bottom line
Anti-scraping laws are not a single rulebook, but they do create real obligations for sites that expose data online. The safest response is to combine clear policy, careful data handling, and adaptive technical controls. That way you can reduce abuse, protect sensitive data, and avoid turning routine automation into a compliance problem.
Where to go next: review the docs or check pricing if you want to evaluate a bot-defense layer for your application.