
Anti web scraping tools are systems that detect, challenge, rate-limit, or block automated collection of your site’s content and data. The practical goal is not to “stop all bots” — that is unrealistic — but to make scraping expensive, noisy, and unreliable enough that abuse drops below your risk threshold while real users keep moving.
If you’re deciding whether to add anti web scraping tools, start with the problem they solve: credential stuffing, content theft, price scraping, inventory hoarding, and data scraping that overloads origin servers or distorts your business metrics. The right setup combines client-side signals, server-side validation, and policy controls. A CAPTCHA alone is rarely the whole answer.
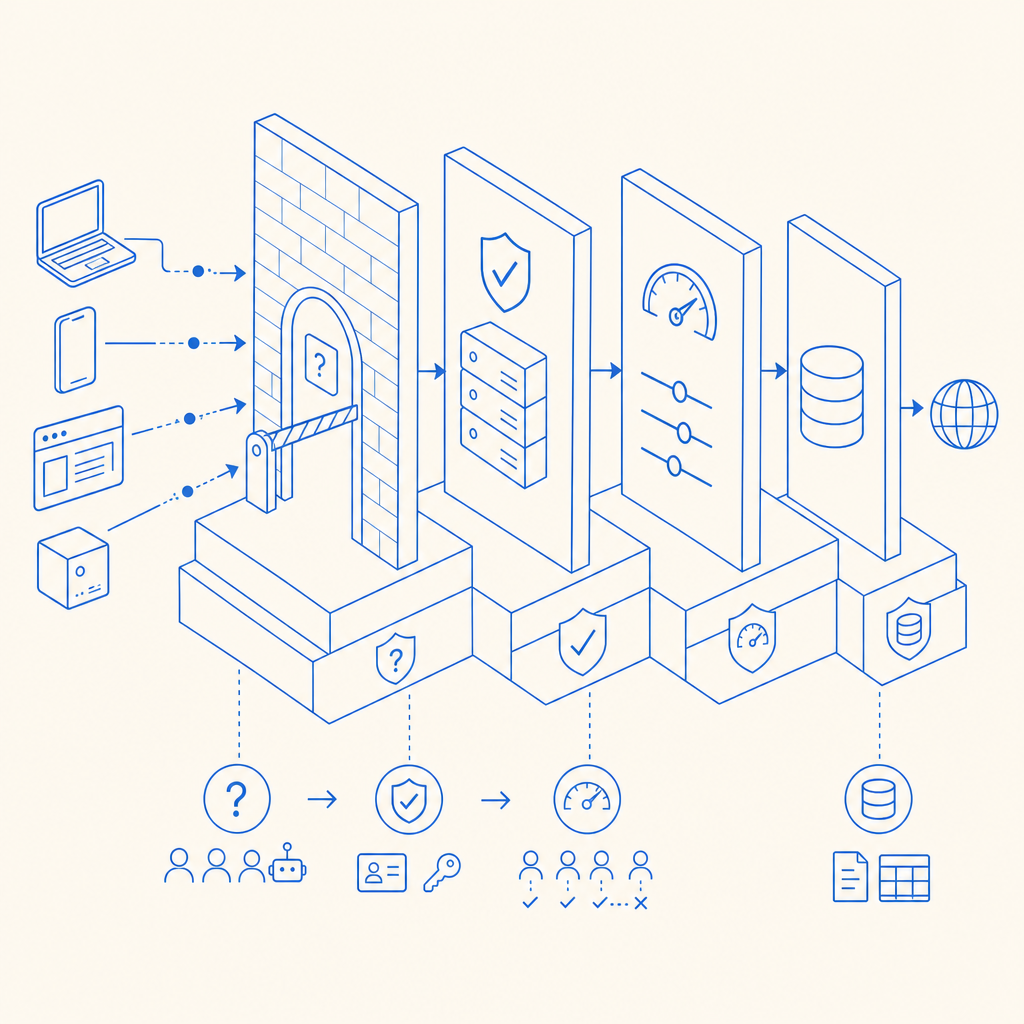
What anti web scraping tools actually do
Most anti web scraping tools sit in front of sensitive endpoints or form flows and apply one or more of these controls:
Challenge-based friction
A bot must complete a puzzle, proof-of-work step, or interaction check before continuing. This is where products like reCAPTCHA, hCaptcha, Cloudflare Turnstile, and CaptchaLa often enter the picture. They differ in privacy model, user experience, and integration style.Behavioral and request analysis
Tools examine velocity, navigation paths, header consistency, IP reputation, cookie behavior, and session continuity. A scraper that requests hundreds of product pages in a fixed pattern is easier to flag than a human browsing normally.Token validation
A client receives a pass token after passing a challenge. Your backend validates that token before allowing the action. This keeps trust decisions server-side instead of relying on the browser alone.Traffic shaping
Rate limits, device binding, and endpoint-specific controls reduce the value of automation even when a bot gets through one layer.
A good anti-scraping setup doesn’t just ask “human or bot?” It asks “how confident are we, what action is being attempted, and how much friction is acceptable for this endpoint?”
Common tool categories
| Category | Typical strength | Typical tradeoff | Best for |
|---|---|---|---|
| CAPTCHA / interaction challenge | High friction for automation | Can add user friction | Signup, login, checkout, sensitive forms |
| Behavioral detection | Low user friction | Can be fooled by advanced bots | Content pages, login abuse, scraping detection |
| Rate limiting | Simple and reliable | Coarse control | API endpoints, high-volume pages |
| WAF / edge bot rules | Good scale protection | Requires tuning | Large sites, traffic spikes |
| Session/token validation | Strong backend trust | Needs integration work | Any action that changes state |
Signals defenders rely on
Anti web scraping tools are only as good as the signals they can combine. One weak signal rarely proves automation; a cluster of weak signals often does.
Useful signals include
- IP and ASN reputation: Residential, datacenter, and proxy networks behave very differently.
- Request timing: Humans pause, scroll, and hesitate; scrapers often march at consistent intervals.
- Navigation entropy: Real users rarely hit 500 product URLs in numeric order.
- Browser integrity: Missing APIs, inconsistent user agents, and malformed client hints can indicate automation.
- Cookie and storage continuity: A session that never persists state looks suspicious.
- Challenge success pattern: Repeated challenge failures or impossible pass rates are strong indicators.
- Endpoint sensitivity: Login, password reset, checkout, search, and pricing pages deserve different thresholds.
The most useful systems treat these signals as a scoring problem, not a single yes/no test. That matters because scrapers adapt. If your defense relies on one brittle check, automation will route around it.
For example, a team might allow anonymous browsing of blog content but challenge rapid access to pricing pages or internal search. That is more practical than locking everything behind a hurdle.
How to choose the right setup
Choosing anti web scraping tools is mostly about matching control strength to business impact. If a scraper only copies a public blog post, you may tolerate lighter friction. If it can distort inventory, scrape pricing at scale, or drain API budgets, you need stronger server-side enforcement.
A simple decision framework:
Map your high-value targets
Identify pages, forms, and API routes that produce the most abuse or the most business risk.Define acceptable friction
Ask how much extra work a real visitor can tolerate on each flow. Login can handle more friction than read-only browsing.Decide where trust lives
If the browser decides everything, bots can tamper with the decision. Prefer a server validation step for anything sensitive.Measure false positives
Good anti web scraping tools should not punish legitimate users at scale. Watch completion rates, abandonment, and support tickets.Plan for rollout
Start in monitoring or soft-challenge mode, then tighten controls once you understand normal traffic patterns.
Here is a practical implementation pattern that keeps the decision on your backend:
// Client flow
// 1. User completes challenge
// 2. App receives pass token
// 3. App sends pass token and client IP to backend
// Server flow
// 4. Backend validates token with provider
// 5. Backend checks action context and risk score
// 6. Backend allows or denies the requestThat basic structure is important because it avoids trusting the front end as the source of truth. If a bot can modify browser code, it can usually bypass a purely client-side gate.
Integration details that matter
Many teams underestimate how much integration quality affects results. The same category of tool can feel smooth or painful depending on how it ships.
If you want a flexible setup, look for:
- Multiple frontend frameworks and mobile SDKs
- Server-side validation APIs
- Clear challenge issuance flow
- A small footprint loader
- Localized UI support
- Documentation that explains token lifecycle and retry handling
CaptchaLa is one option in this space. It supports 8 UI languages and native SDKs for Web (JS, Vue, React), iOS, Android, Flutter, and Electron. For backend validation, it exposes a validation endpoint at POST https://apiv1.captcha.la/v1/validate using pass_token and client_ip with X-App-Key and X-App-Secret. It also supports server-token issuance through POST https://apiv1.captcha.la/v1/server/challenge/issue. If you want the implementation details, the docs are the place to start.
Package availability matters too when you’re standardizing across teams. CaptchaLa provides Maven la.captcha:captchala:1.0.2, CocoaPods Captchala 1.0.2, pub.dev captchala 1.3.2, plus server SDKs for captchala-php and captchala-go. The loader script is https://cdn.captcha-cdn.net/captchala-loader.js.
If you’re comparing vendors, the objective questions are usually the same:
- Does it support server-side verification?
- How easy is it to localize and embed?
- Can you tune friction by route?
- Does it fit web and mobile?
- How transparent are logs and failure modes?
Cloudflare Turnstile is attractive for low-friction experiences; hCaptcha is often chosen where challenge economics matter; reCAPTCHA remains widely recognized. Each has a place, but the right pick depends on your traffic, privacy posture, and operational tolerance.
A practical anti-scraping stack
The strongest deployments rarely depend on one control. They combine layers.
Edge filtering
Block obvious bad traffic with WAF rules, ASN restrictions, or geo policies where appropriate.Challenge on risk
Trigger a CAPTCHA or similar challenge only when behavior crosses a threshold.Backend validation
Verify the pass token before sensitive actions, never just in the browser.Endpoint-specific rate limits
Set different ceilings for search, login, checkout, and scrape-prone read endpoints.Logging and review
Track solve rates, challenge frequency, and denial reasons so you can tighten or relax rules with evidence.Iterate on false positives
Scrapers evolve, but so do legitimate traffic patterns. Revisit thresholds regularly.

Final takeaway
Anti web scraping tools work best when they reduce automation value without turning your product into a maze for real users. Start with your highest-risk routes, validate on the server, and measure the impact before you tighten anything further. If you need a place to compare integration details or pricing tiers, take a look at pricing and the docs.