
Preventing unauthorized data extraction, or anti web scraping, is essential for protecting your website’s content, user data, and business value from automated bots. Anti web scraping measures help distinguish legitimate users from aggressive scrapers that may overload your servers, steal proprietary content, or manipulate your services unfairly. By implementing a layered bot-defense strategy, websites and SaaS platforms can reduce abusive scraping, maintain service quality, and uphold data integrity.
What Is Anti Web Scraping?
Anti web scraping refers to techniques and tools designed to detect and block automated scripts that collect data from websites without permission. Often, web scrapers mimic human behavior to evade simple defenses, but their activity patterns differ enough that sophisticated systems can identify them. Anti scraping strategies use a combination of technical controls and behavioral analysis to minimize unwanted extraction while preserving a smooth experience for genuine users.
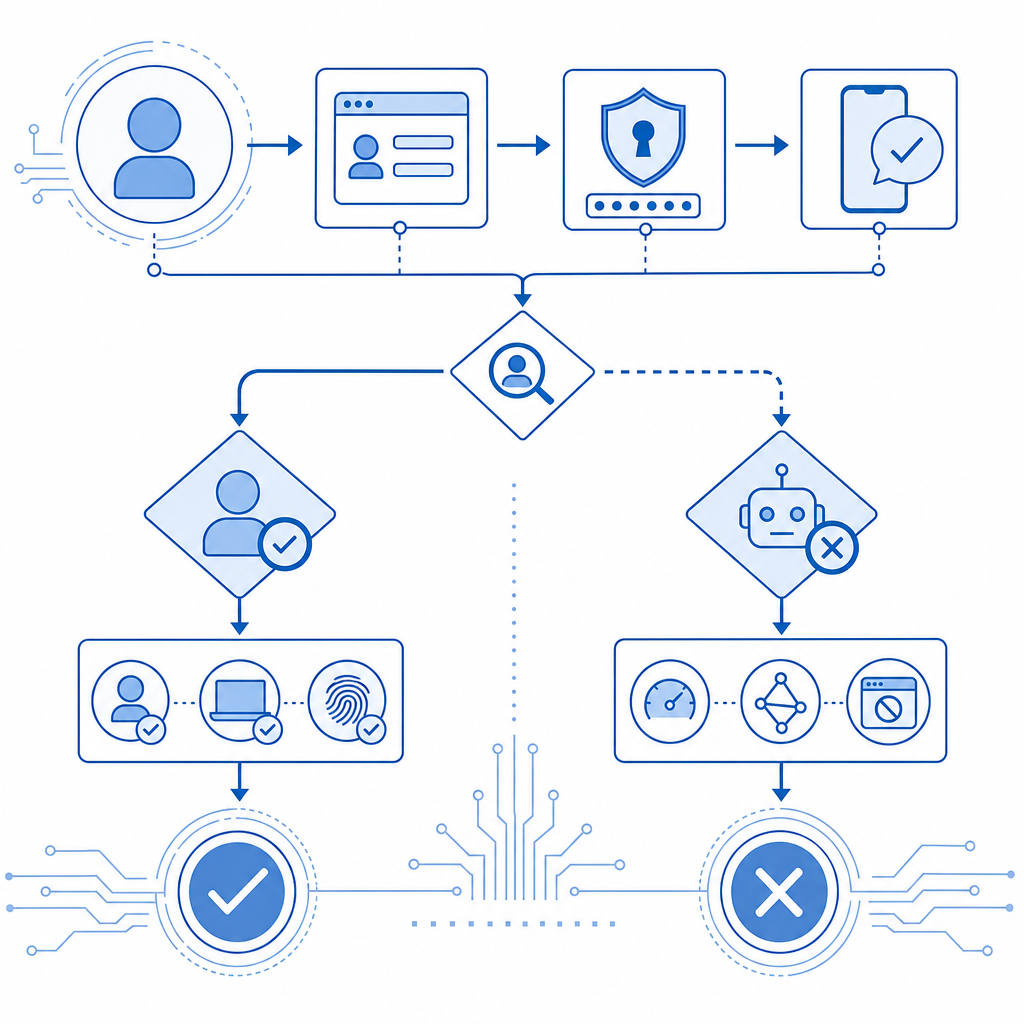
While traditional firewalls and IP blocking can help, modern scrapers adapt quickly. Site owners must therefore deploy dynamic bot-defense solutions with capabilities like CAPTCHA challenges, rate limiting, fingerprinting, and bot traffic analysis to stay ahead.
Core Techniques for Anti Web Scraping
1. CAPTCHA Challenges
CAPTCHAs force users to solve puzzles or tasks that are easy for humans but difficult for automated bots. Commonly used CAPTCHAs like Google's reCAPTCHA and hCaptcha verify user authenticity but sometimes impact user experience with unnecessary friction. Newer alternatives, such as Cloudflare Turnstile or CaptchaLa, aim to balance security and UX by using invisible or low-friction CAPTCHA challenges that selectively activate based on trust signals.
2. Rate Limiting & IP Reputation
Limiting the number of requests per IP or user session can slow down scraping activity. Coupled with IP reputation databases, this helps block known malicious actors. However, scrapers often use distributed proxies to circumvent static limits, requiring adaptive rate controls and behavioral analysis.
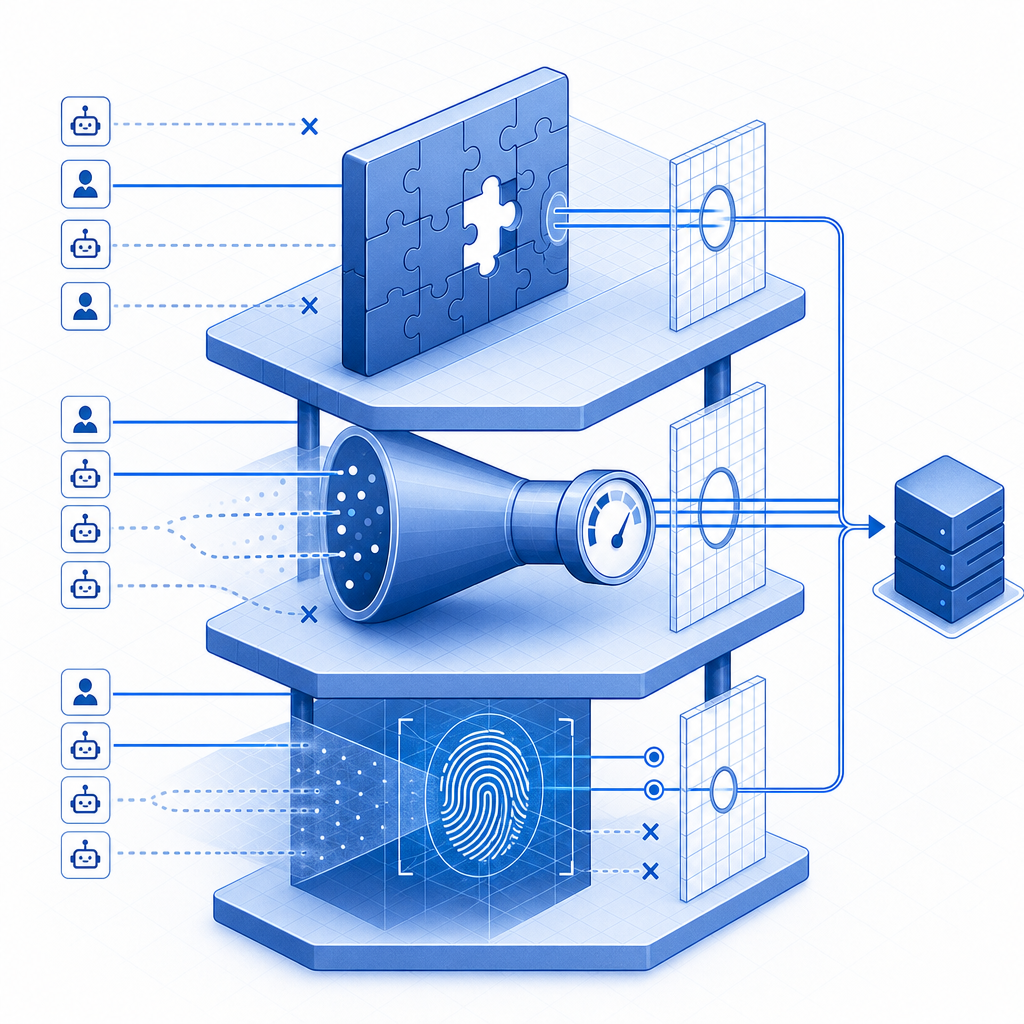
3. Browser Fingerprinting and Device Profiling
Fingerprinting analyzes user agents, browser properties, and device traits to differentiate real users from bots. When combined with anomaly detection (e.g., sudden bursts or abnormal navigation patterns), it offers a powerful signal to trigger additional verification or blocking.
4. Honeypot Traps and JavaScript Challenges
Invisible fields or JavaScript executions that human users never activate catch unsophisticated bots. Bots that do not execute scripts or fill invisible form elements can be identified with these methods.
5. Behavioral Analysis and Machine Learning
Advanced platforms monitor visitor behavior over time to detect suspicious activity patterns. Sessions exhibiting rapid page access, scraping-specific endpoint usage, or non-human navigation flow can be flagged for mitigation with CAPTCHAs or throttling.
Comparing Popular Anti Web Scraping Solutions
| Feature | reCAPTCHA | hCaptcha | Cloudflare Turnstile | CaptchaLa (Our SaaS) |
|---|---|---|---|---|
| Challenge Type | Visual puzzles, audio | Visual puzzles | Invisible, passive | Selective/layered CAPTCHAs |
| User Experience | Moderate friction | Moderate friction | Low friction | Low friction, dynamic |
| SDKs & Platform Support | Web, mobile | Web, mobile | Web only | Web, iOS, Android, Flutter, Electron |
| Multiple UI Languages | Limited | Limited | Limited | 8 native UI languages |
| Server-side Validation | Yes | Yes | Yes | Yes (with server SDKs PHP, Go) |
| Pricing Model | Free, enterprise tiers | Enterprise pricing | Part of Cloudflare | Free tier + scalable paid plans |
CaptchaLa’s range of native SDKs for web frameworks (JS, React, Vue) and mobile platforms (iOS, Android, Flutter) simplifies integration for development teams. Its flexible validation API and straightforward token issuing allow fine-grained control over challenge triggering and user verification workflows.
Implementing Anti Web Scraping with CaptchaLa
Here’s a simple example of integrating CaptchaLa to trigger a CAPTCHA challenge during suspicious activity:
// Client-side: Load CaptchaLa widget during login or high-risk events
import { loadCaptcha } from 'captchala-sdk';
async function verifyUser() {
const token = await loadCaptcha();
if (token) {
const response = await fetch('/api/validate', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ pass_token: token, client_ip: getClientIP() }),
});
const result = await response.json();
if (result.success) {
// User verified, allow access
} else {
// Prompt retry or block access
}
}
}On the server side, validate this token using CaptchaLa’s secure API endpoint:
// PHP server validation example
$passToken = $_POST['pass_token'];
$clientIp = $_POST['client_ip'];
$response = validateCaptchaLaToken($passToken, $clientIp);
if ($response->success) {
// Proceed with request
} else {
// Reject request or show error
}Integration with CaptchaLa provides a smooth balance between user convenience and effective bot detection.
Best Practices for Anti Web Scraping Defense
- Layer Your Defenses: Combine CAPTCHAs, rate limiting, behavioral analysis, and fingerprinting for a multi-faceted approach.
- Adapt and Monitor: Regularly analyze traffic patterns to update risk thresholds and detection rules against evolving scraping tactics.
- Minimize User Friction: Use invisible or challenge-on-demand CAPTCHAs to avoid disrupting genuine users.
- Leverage Third-Party Tools Judiciously: Evaluate services like CaptchaLa, reCAPTCHA, or Cloudflare Turnstile based on your platform needs, data privacy considerations, and customization options.
- Implement Server-Side Checks: Validate every CAPTCHA pass token server-side to prevent token reuse or bypass attempts.
Developers can choose to incorporate anti web scraping into their product pipeline early on, maintaining site integrity as data grows more valuable and attack vectors more sophisticated.
In summary, effective anti web scraping requires combining technology, adaptive monitoring, and user-centric design. CaptchaLa offers an accessible toolset with multi-platform support and flexible deployment options for teams wanting to shift from reactive blocking toward proactive bot mitigation.
To explore detailed documentation or pricing plans for scalable bot defense tailored to your site, visit CaptchaLa docs and pricing. Establish stronger control over your web assets today with smarter anti web scraping measures.