
Anti scraping website technologies are essential tools designed to detect, block, and mitigate unauthorized data extraction attempts by automated bots. These technologies vary in complexity but ultimately serve to safeguard a site’s content, user data, and server resources by differentiating between human visitors and scripted crawlers.
Web scraping, when uncontrolled, can lead to data theft, degraded server performance, unfair competitive advantages, and privacy violations. To counteract this, site owners deploy a combination of methods including CAPTCHA challenges, behavior analysis, IP reputation checks, and rate limiting. Understanding how these anti scraping technologies work—and their advantages and trade-offs—is key to selecting an effective bot defense strategy.
Core Techniques Behind Anti Scraping Website Technologies
Anti scraping measures today leverage a multi-layered approach combining client-side and server-side defenses:
1. CAPTCHA and Interactive Challenges
CAPTCHAs require users to solve visual puzzles, click specific images, or complete interactive games to prove humanity. Technologies like CaptchaLa provide fully customizable CAPTCHA systems supporting multiple UI languages and SDKs for web and mobile platforms. Other popular solutions include Google’s reCAPTCHA, hCaptcha, and Cloudflare Turnstile, each with different modes for balancing usability and security.
2. Behavioral and Fingerprinting Analytics
These systems monitor mouse movements, keystroke timing, and browsing patterns to detect non-human behavior common to automated tools. Fingerprinting may also include device, browser, and network characteristics to uniquely identify clients even if IP addresses rotate.
3. Rate Limiting and Access Controls
Blocking or throttling IP addresses or accounts that exhibit suspiciously high request rates prevents mass scraping. Combined with IP reputation databases, this can instantly blacklist known operators of scrapers and bot farms.
4. JavaScript and Bot Detection
Dynamic JavaScript challenges test a client's ability to execute code like typical browsers. Many basic scraping bots have limited JavaScript engines, so this raises the bar. This method is often used in conjunction with CAPTCHAs to increase bot detection accuracy.
Comparison of Popular CAPTCHA/Bot-Defense Providers
| Feature | CaptchaLa | reCAPTCHA | hCaptcha | Cloudflare Turnstile |
|---|---|---|---|---|
| Supported Platforms | Web (JS/Vue/React), iOS, Android, Flutter, Electron | Web, mobile SDKs | Web, mobile SDKs | Web, integrated with Cloudflare |
| UI Language Support | 8 languages | Multiple languages | Multiple languages | Limited |
| Server SDKs | PHP, Go | Various language SDKs | Multiple languages | Cloudflare proprietary |
| Privacy Focus | First-party data only | Data shared with Google | Privacy-focused | Cloudflare data |
| Pricing | Free tier + scalable plans (pricing) | Free with Google account | Usage-based | Included with Cloudflare plans |
| Customization | Extensive | Moderate | Moderate | Low |
Choosing the right tool depends on factors like budget, privacy requirements, integration complexity, and user experience expectations.
Implementing Effective Anti Scraping Strategies
Successful anti scraping involves a combination of technical layers and policies tailored to your website’s risk profile.
Step-by-Step Technical Measures
Use a reliable CAPTCHA provider
Integrate CAPTCHAs that offer seamless user experiences without compromising security. For example, CaptchaLa supports native SDKs and flexible UI options adaptable to various platforms.Deploy behavioral analytics
Analyze client interactions to detect anomalies indicating bot activity. This can reduce false positives from legitimate users who have difficulty with puzzles alone.Set rate limits
Establish thresholds for maximum request rates per IP, user-agent, or session. Use server logs or analytics to identify spikes in access patterns.Leverage IP reputation services
Block or challenge visitors from known high-risk IP addresses or cloud providers frequently abused by scrapers.Implement JavaScript challenges
Require clients to execute certain scripts to prove browser capability, filtering out basic HTTP client scrapers.
Here's a simplified example of server-side validation flow for CAPTCHA tokens in a PHP environment using CaptchaLa’s API:
<?php
// Receive POST data: pass_token and client_ip
$pass_token = $_POST['pass_token'];
$client_ip = $_POST['client_ip'];
// Endpoint and credentials for CaptchaLa API
$validate_url = "https://apiv1.captcha.la/v1/validate";
$app_key = "YOUR_APP_KEY";
$app_secret = "YOUR_APP_SECRET";
// Prepare request payload
$data = json_encode([
'pass_token' => $pass_token,
'client_ip' => $client_ip
]);
// cURL setup for POST request
$ch = curl_init($validate_url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_POST, true);
curl_setopt($ch, CURLOPT_HTTPHEADER, [
"Content-Type: application/json",
"X-App-Key: $app_key",
"X-App-Secret: $app_secret"
]);
curl_setopt($ch, CURLOPT_POSTFIELDS, $data);
// Execute request and decode response
$response = curl_exec($ch);
curl_close($ch);
$result = json_decode($response, true);
if ($result && isset($result['success']) && $result['success'] === true) {
// CAPTCHA passed - proceed with request
} else {
// CAPTCHA failed or invalid - block or challenge again
}
?>This example highlights how server-side validation is essential, avoiding reliance on client-side trust alone.
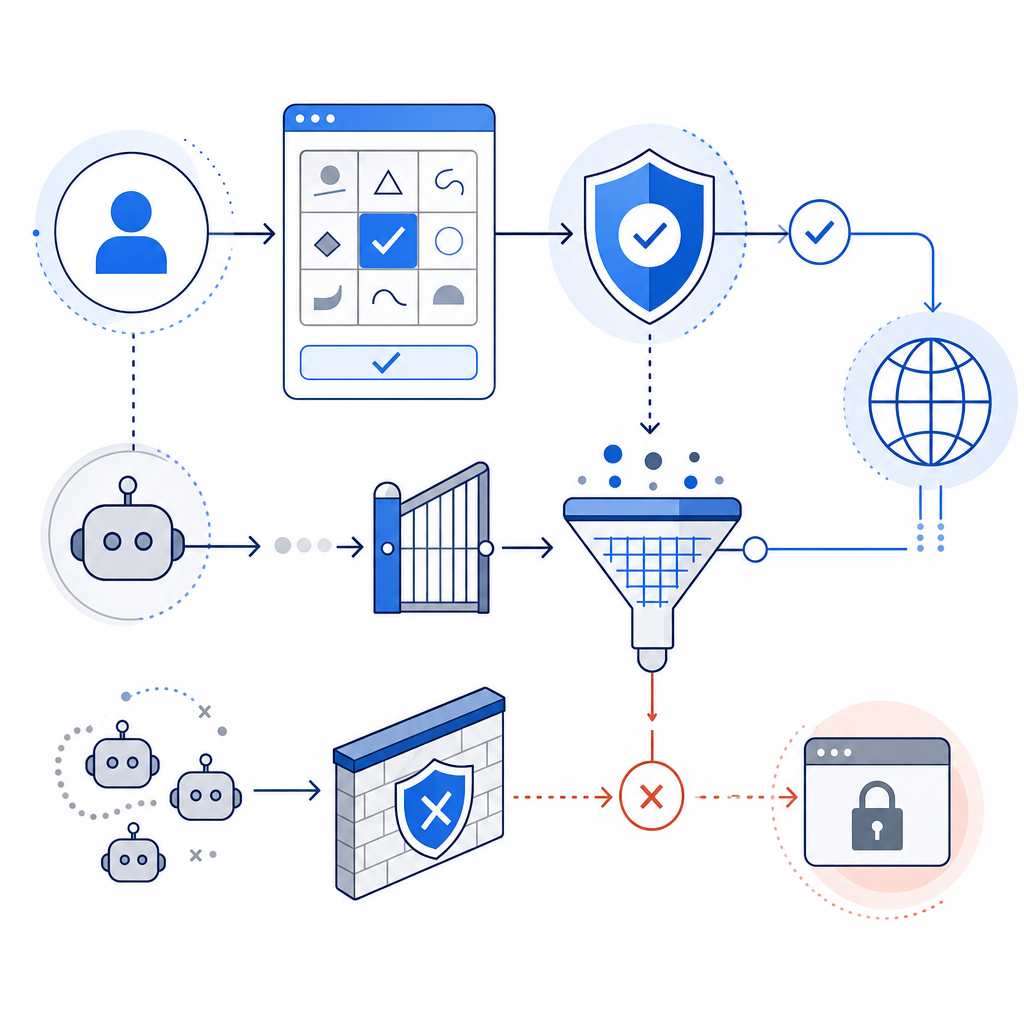
Balancing User Experience and Security
Effective anti scraping systems must minimize disruptions for legitimate users while blocking malicious bots. Overly aggressive CAPTCHA deployments can deter genuine visitors, reduce conversions, and frustrate accessibility needs. This is why adaptive challenges, behavior analysis, and silent bot detection are increasingly popular.
Providers like CaptchaLa provide options for invisible or low-interaction modes to reduce the burden on users. Meanwhile, competitors such as Cloudflare Turnstile focus on frictionless bot detection with low user impact but require Cloudflare integration.
When choosing technologies, consider user demographics, threat models, and tolerance for risk vs friction.
Conclusion
Anti scraping website technologies incorporate CAPTCHAs, behavior-based detection, rate limiting, IP reputation, and JavaScript challenges to protect websites from automated data extraction. Combining multiple defenses creates a robust shield against scrapers while preserving user experience.
Solutions like CaptchaLa offer extensive SDK support across web and mobile, multiple language options, and server SDKs to help developers integrate sophisticated bot defense. Alongside alternatives like reCAPTCHA, hCaptcha, and Cloudflare Turnstile, they form a diverse ecosystem enabling websites to fight unauthorized scraping effectively.
Where to go next? Explore CaptchaLa pricing to find a plan that fits your needs or dive deeper into technical implementation via the docs. Protecting your website’s data starts with choosing the right tools and strategies.