
An anti scraping website is designed to detect, prevent, and mitigate automated data extraction by bots without compromising legitimate user experience. Preventing scraping is vital to protect proprietary content, maintain fair usage, and safeguard customer data. Effective anti scraping solutions combine multiple techniques such as behavior analysis, rate limiting, and challenges like CAPTCHAs to distinguish human users from bots.
Why Do You Need an Anti Scraping Website?
Web scraping—automated extraction of website data—can be malicious or competitive scraping, leading to revenue loss, server overload, and intellectual property risks. Unlike basic firewalls or IP blocks, anti scraping websites utilize sophisticated mechanisms that adapt to evolving bot tactics. A comprehensive approach not only blocks unauthorized access but also preserves the usability and speed for real human visitors.
Key reasons include:
- Protecting content value — Preventing competitors from copying product listings, pricing data, or proprietary articles.
- Improving site performance—Avoiding traffic spikes from scraping bots that can degrade server response times.
- Preventing data theft and fraud — Avoiding harvesting of personal information or credentials.
- Maintaining analytics accuracy — Filtering out bot traffic to preserve clean user metrics.
Core Techniques Behind Anti Scraping Websites
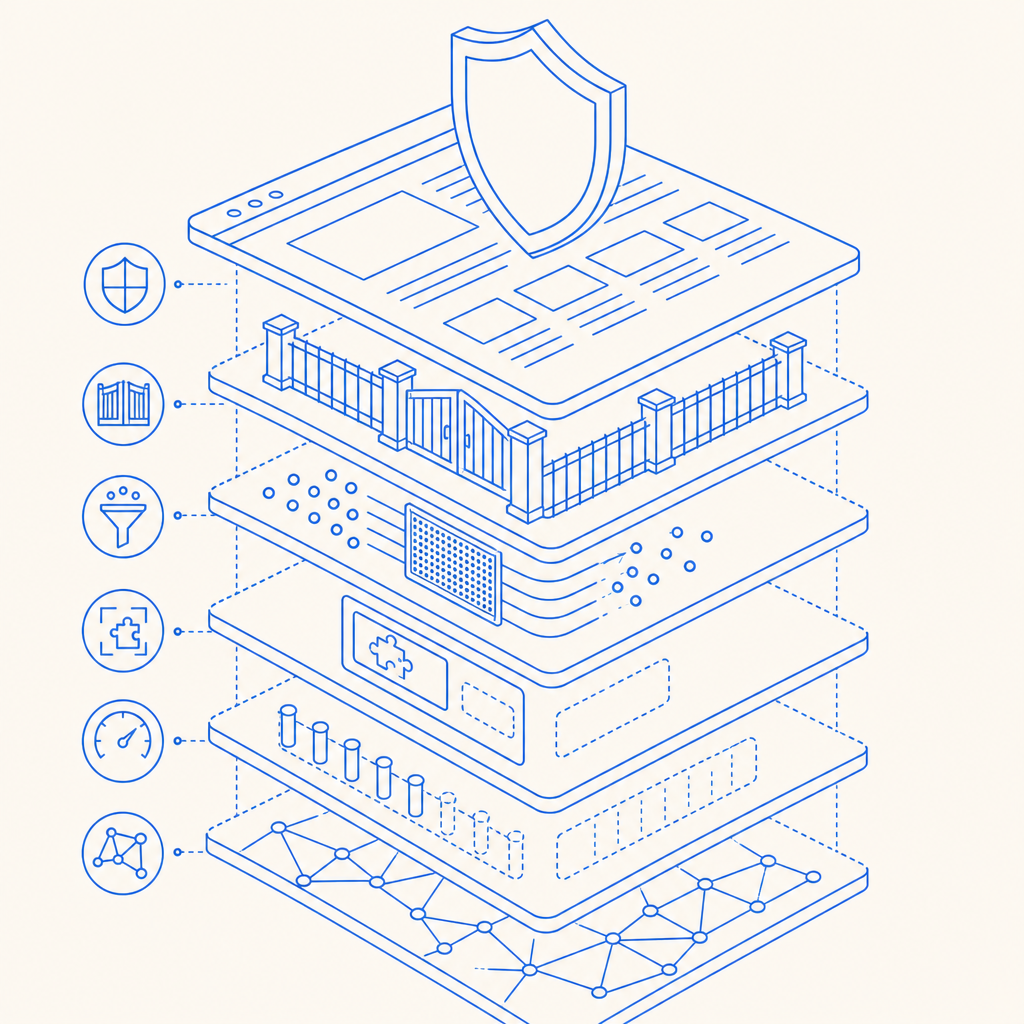
To build a robust anti scraping website, deploy a mix of layers that inspect user behavior, network patterns, and request signals.
1. Rate Limiting & IP Reputation
Throttle repeated requests from the same IP or region. Blocking known malicious IPs through threat intelligence feeds can prevent some scraping attempts but is insufficient alone since many bots use proxies or large IP pools.
2. Device & Browser Fingerprinting
Fingerprint based on browser headers, screen resolution, plugins, and other attributes to identify suspicious automated clients masquerading as normal browsers.
3. Behavioral Analysis & Machine Learning
Track mouse movements, scroll patterns, and interaction timing to differentiate bots that lack human-like randomness. ML models can flag anomalies indicative of scraping.
4. Challenge-Response Tests (CAPTCHAs)
Presenting CAPTCHAs like those offered by CaptchaLa challenges user scripts that cannot solve puzzles, especially under high-risk conditions or after suspicious behavior is detected.
Comparing Popular CAPTCHA Solutions for Anti Scraping
CAPTCHAs remain a cornerstone of anti scraping design by actively verifying human presence. Here’s a quick look at some major providers:
| Feature | CaptchaLa | Google reCAPTCHA | hCaptcha | Cloudflare Turnstile |
|---|---|---|---|---|
| UI Languages | 8 | Multiple | Multiple | Multiple |
| SDK Support | Web, iOS, Android, Flutter | Web, mobile | Web, mobile | Web only |
| Server-Side SDKs | PHP, Go | Limited | Limited | Not publicly documented |
| Privacy | First-party data only | Google data collection | Third party data usage | Cloudflare data collection |
| Free Tier Quotas | 1000 requests/month | Unlimited (with limits) | Free with gating | Unlimited |
| Customization | Moderate | Moderate | Moderate | Low |
While Google’s reCAPTCHA dominates due to widespread adoption, alternatives like CaptchaLa provide native SDKs supporting more platforms including Electron and Flutter, as well as server tools like captchala-php and captchala-go for flexible integration. This makes CaptchaLa an accessible option if you need multi-platform support with privacy considerations.
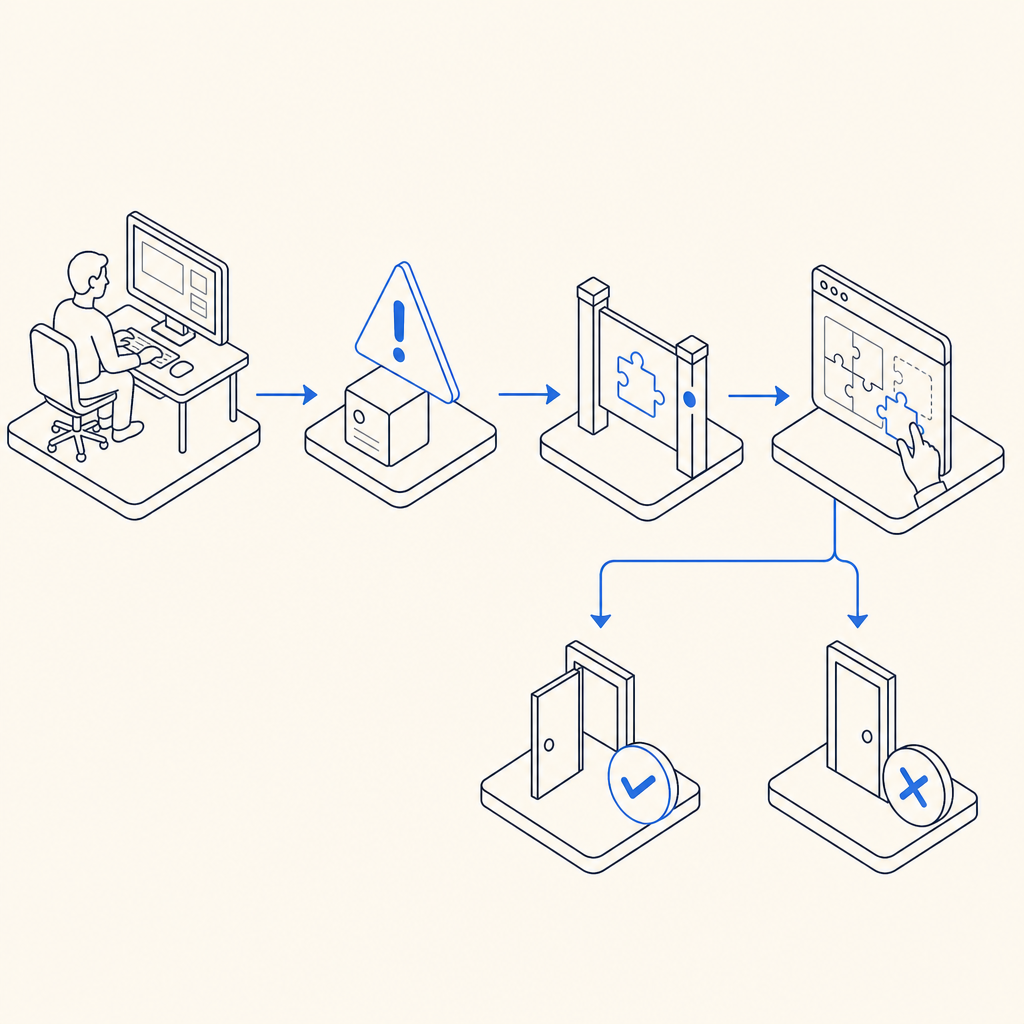
Building an Anti Scraping Website with CaptchaLa
Integrating bot defense through CaptchaLa involves layering challenge-response validation where suspicious activity is detected.
Step-by-step technical specifics:
Client-Side Integration
Load the lightweight CaptchaLa script to trigger challenges on forms or during user interactions:javascript// Load CaptchaLa loader script for client challenges <script src="https://cdn.captcha-cdn.net/captchala-loader.js"></script>Challenge Issuance
On the server, request a challenge token before showing the CAPTCHA:php// Issue a server challenge token (PHP example) $response = file_get_contents("https://apiv1.captcha.la/v1/server/challenge/issue", false, stream_context_create([ 'http' => [ 'method' => 'POST', 'header' => "X-App-Key: your_key\r\nX-App-Secret: your_secret\r\n", ], ])); $challengeToken = json_decode($response)->token;Validation of Responses
After user attempts the CAPTCHA, validate via API whether the token and IP correspond to a successful human validation:go// Validate CAPTCHA token (Go example) req, _ := http.NewRequest("POST", "https://apiv1.captcha.la/v1/validate", bytes.NewBuffer([]byte(`{"pass_token":"token_here","client_ip":"user_ip"}`))) req.Header.Set("X-App-Key", "your_key") req.Header.Set("X-App-Secret", "your_secret") // send request and parse response ...Action Based on Validation
Allow, restrict, or flag access depending on validation outcome.
Additional recommendations:
- Combine with real-time monitoring and alerts for spikes in suspicious traffic.
- Use behavioral analytics for progressive CAPTCHA triggering rather than frustrating every user.
- Regularly update IP blocklists and fingerprinting heuristics.
Beyond CAPTCHAs: Why Multiple Layers Matter
While CAPTCHAs like CaptchaLa’s provide effective gatekeeping, sophisticated scrapers may try to imitate humans or distribute scraping over many IPs. Combining CAPTCHAs with rate limits, fingerprinting, and ML-driven behavioral detection forms a comprehensive anti scraping website.
Competitors such as Cloudflare Turnstile offer passwordless, seamless challenge options aimed at user convenience but may lack some platform integrations needed in diverse application environments.
Conclusion
Creating an effective anti scraping website requires a deliberate, layered approach that balances strong bot detection with preserving user experience. CAPTCHA solutions remain a critical component, and tools like CaptchaLa offer versatile SDKs and APIs to customize defenses across platforms.
Start by assessing your traffic patterns, integrate CAPTCHA challenges for suspicious sessions, and continuously refine your defenses with behavioral data and IP intelligence.
For more technical details and pricing plans, explore CaptchaLa’s documentation or review the latest pricing options. Building robust scraping defenses today will help you maintain control over your web content and deliver a secure, smooth user experience tomorrow.