
Anti scraping prohibition refers to the set of technical and legal measures implemented by website owners to prevent automated scraping tools from extracting data without permission. It involves detecting and blocking bots that attempt to harvest content, pricing, user information, or other sensitive data, helping preserve site integrity and privacy. This concept is critical because scraping, if uncontrolled, can strain server resources, violate terms of service, and expose proprietary or personal data.
What Does Anti Scraping Prohibition Mean in Practice?
At its core, anti scraping prohibition means actively stopping unauthorized automated access to web data. Websites deploy various strategies—both technical controls like CAPTCHAs and rate limiting, and legal notices like terms of service prohibitions—to make scraping costly, difficult, or legally risky. While web data is publicly accessible by default, scraping prohibition aims to differentiate legitimate human visitors from bots that crawl pages at scale.
Many companies view scraping as an infringement on intellectual property, unfair competitive behavior, or a vector for spam and account takeover attacks. Anti scraping prohibition is thus a defensive posture combining technology, monitoring, and policy to reduce malicious scraping activity without impacting real users.
Common Technical Measures Enforcing Anti Scraping Prohibition
1. CAPTCHA and Bot Detection Challenges
CAPTCHAs remain a staple defense, pausing suspicious traffic to verify humanity. Solutions like CaptchaLa provide configurable user challenges that adapt to different threat levels, minimizing friction while deterring automated harvesters.
| Feature | CaptchaLa | reCAPTCHA (Google) | hCaptcha | Cloudflare Turnstile |
|---|---|---|---|---|
| SDKs | Web, iOS, Android, Flutter, Electron | Primarily Web & Mobile SDKs | Web & Mobile SDKs | Web-focused |
| Languages | 8 UI languages | Multiple languages | Multiple languages | Multiple languages |
| Pricing | Free tier + Pro + Business tiers | Free; Enterprise pricing | Free + paid plans | Free, part of Cloudflare CDN |
| Data Privacy | First-party data only | Google data sharing | Privacy-focused | Requires Cloudflare network |
| Customization | High | Medium | Medium | Limited |
2. Rate Limiting and Traffic Analysis
Blocking IP addresses or throttling request rates helps prevent scraping bots from overwhelming servers. Many sites integrate bot analytics to identify unusual patterns like burst requests or known bot signatures. This tactic pairs well with other tools but risks false positives without fine-tuning.
3. JavaScript and Behavioral Checks
Some anti scraping systems evaluate JavaScript execution capabilities and user interaction patterns to distinguish bots from humans. Bots that do not interpret JavaScript or fail mouse movement and timing heuristics can be flagged for further challenge.
Legal and Policy Dimensions of Anti Scraping Prohibition
Many websites specify anti scraping clauses in their Terms of Service (ToS), making unauthorized scraping a breach subject to legal action. This adds a deterrent effect alongside technical barriers. However, enforcement varies by jurisdiction and level of resources.
Policies often prohibit automated data extraction but explicitly allow search engine crawling or user agents that comply with robots.txt files. This differentiation guides scraper behavior and legitimizes beneficial automation.
To summarize key legal points:
- Explicit Prohibition: ToS states “No scraping or automated data collection.”
- Robots.txt Directives: Robots exclusion files define crawler permissions.
- Enforcement Threats: Possibility of IP bans, cease-and-desist letters, or lawsuits.
- Respect for Public Interest: Balance between protection and fair use or research needs.
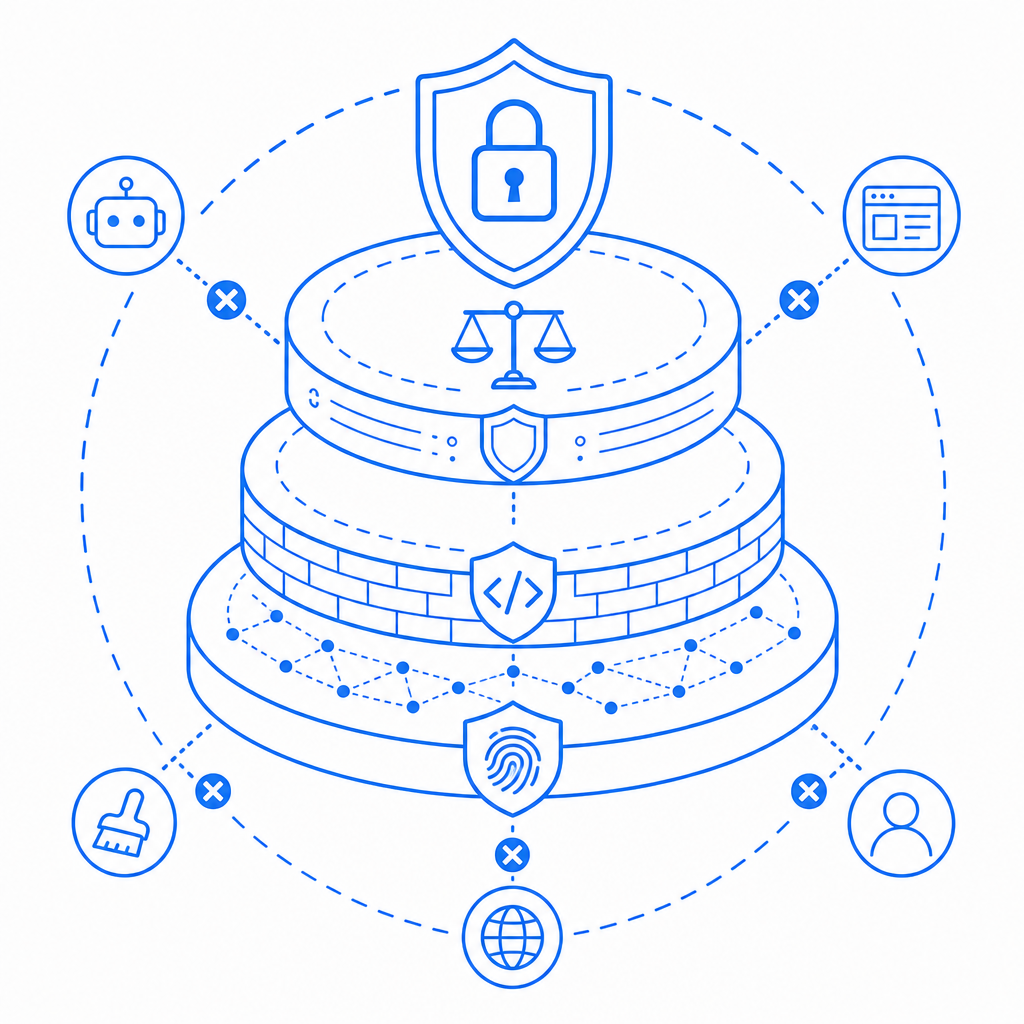
Challenges with Anti Scraping Prohibition
Implementing anti scraping prohibition is complex. Technical measures can slow down or block legitimate users if misconfigured. Scrapers continuously evolve to bypass defenses, using proxies, headless browsers, and human-in-the-loop solutions.
Balancing security, user experience, and data openness requires ongoing analysis and adjustment. Integration of platforms like CaptchaLa help by offering flexible, developer-friendly SDKs and APIs to implement user-friendly bot defenses transparently.
How CaptchaLa Supports Anti Scraping Prohibition
CaptchaLa provides a toolkit specifically designed to mitigate scraping risks by validating requests using challenge tokens checked via secure server-side APIs. It supports multiple development environments with native SDKs for Web frameworks (JS, Vue, React), mobile platforms (iOS, Android, Flutter), and desktop (Electron). With built-in localization (8 UI languages) and scalable tiers from free to business-level volumes, CaptchaLa enables companies to enforce anti scraping policies without friction.
Its API endpoints allow seamless integration:
// Example: Validate CAPTCHA token server-side
POST https://apiv1.captcha.la/v1/validate
Headers:
X-App-Key: your-app-key
X-App-Secret: your-app-secret
Body:
{
"pass_token": "captchala-token-from-client",
"client_ip": "user-ip-address"
}This request ensures your backend accepts only verified human interactions, reducing scraping risk. CaptchaLa’s documentation and pricing information are available at docs and pricing.
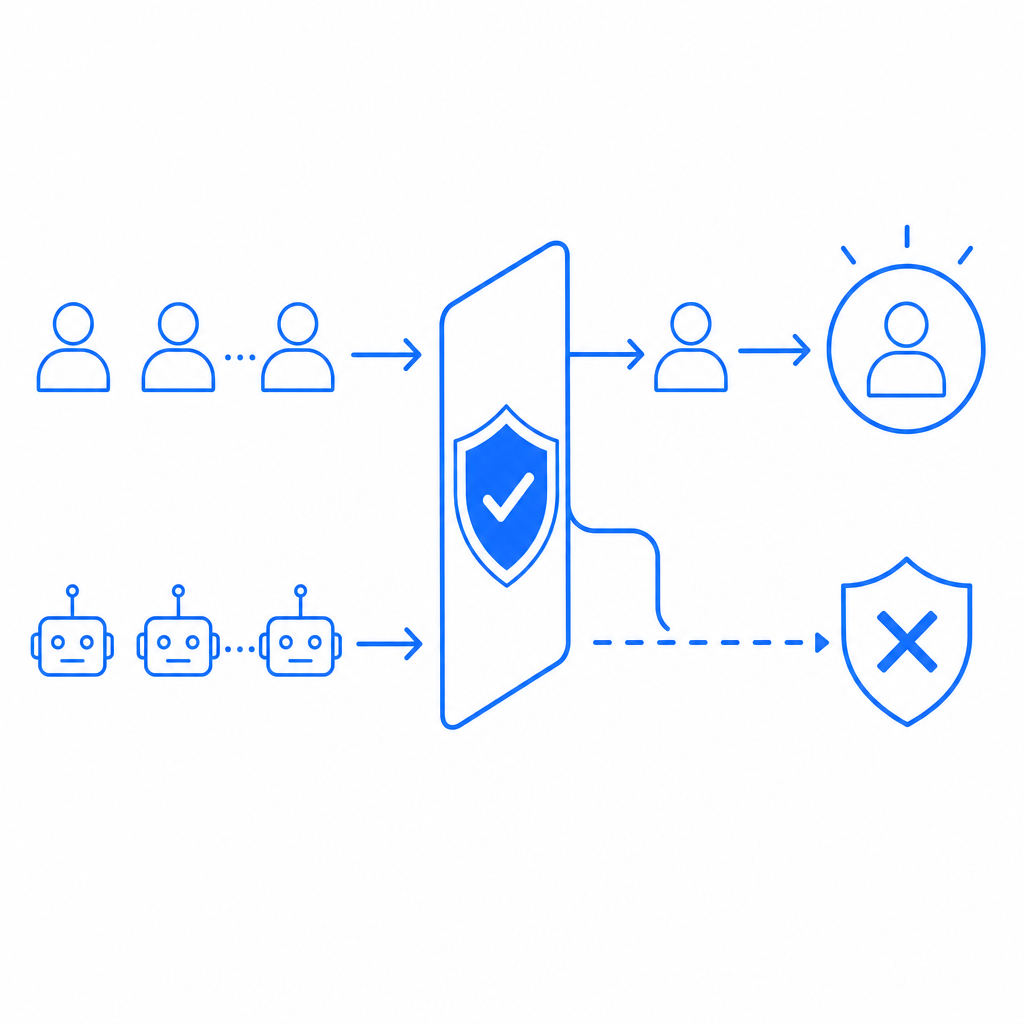
Conclusion
Anti scraping prohibition means deploying a broad defense strategy combining user verification technology, traffic monitoring, and clear policies to prevent unauthorized automated data scraping. Defenses like CAPTCHAs, rate limiting, and legal safeguards work together to secure web assets and ensure fair use.
Platforms such as CaptchaLa offer practical tools designed for diverse tech stacks, making it easier for developers to implement anti scraping protections effectively. When choosing anti scraping solutions, consider factors like integration ease, user experience, privacy, and scalability alongside detection capabilities.
For companies looking to understand or strengthen their anti scraping stance, reviewing tools like CaptchaLa and evaluating your policies and defenses will help maintain control over your web data.
Interested in deploying captures-based anti scraping defenses? Explore CaptchaLa pricing and technical documentation to learn how to start protecting your website today.