
An anti scraping policy is a set of technical and operational measures designed to detect, limit, and block unauthorized automated access—commonly known as scraping—of a website’s content or data. It’s essential because scraping can lead to intellectual property theft, degraded user experience, inflated server costs, and compromised competitive advantages.
At its core, an effective anti scraping policy defines what constitutes acceptable access, outlines detection techniques, enforces rate limits and bot challenges, and integrates monitoring and response systems. This approach balances security needs without frustrating legitimate users or partners.
Why You Need an Anti Scraping Policy
Web scraping tools have become increasingly sophisticated, making it easy for competitors, malicious actors, or aggregators to extract your website data at scale. Some common risks include:
- Data Theft: Proprietary databases, pricing details, and exclusive content can be scraped and reused elsewhere without permission.
- Server Overload: High-volume scraping generates enormous traffic, impacting your website’s performance and availability.
- Distorted Analytics: Automated traffic skews visitor data and interferes with decision-making.
- Security Threats: Scrapers can probe sites for vulnerabilities or attempt account takeover attacks.
Having a clear and enforceable anti scraping policy helps organizations detect these abusive behaviors early and implement mitigating controls tailored to their business needs.
Key Components of a Robust Anti Scraping Policy
A comprehensive policy goes beyond just stating "no scraping allowed." It must include detailed provisions that operationalize that goal.
1. Definition of Prohibited Activities
Specify the behaviors that qualify as scraping, including but not limited to:
- Automated crawling or harvesting large volumes of data without permission.
- Bypassing bot detection tools or scraping anti-bot challenges.
- Using multiple IP addresses or user agents to evade limits.
- Excessive request rates causing service degradation.
This clarity helps legal enforcement and technical teams align on what to detect and block.
2. Detection and Identification Methods
Detecting scrapers is challenging since many leverage techniques to mimic real users. Common detection strategies include:
- Traffic Analysis: Monitoring request rates, session times, and anomalies in user behavior.
- Fingerprinting: Tracking IP addresses, device types, browser headers, and patterns indicative of bots.
- Challenge-Response: Deploying CAPTCHAs and JavaScript challenges to verify human interaction.
- Honeypots: Using hidden fields or traps that legitimate users never trigger.
Many websites incorporate third-party bot defense solutions like CaptchaLa, Google's reCAPTCHA, hCaptcha, or Cloudflare Turnstile. Each has unique capabilities. For example, CaptchaLa provides native SDKs for web frameworks (React, Vue), mobile (iOS, Android), and more, with easy validation APIs to integrate challenges efficiently.
Comparison Table: Popular Bot Defense Providers
| Feature | CaptchaLa | reCAPTCHA | hCaptcha | Cloudflare Turnstile |
|---|---|---|---|---|
| Multi-platform SDKs | Web, iOS, Android, Flutter, Electron | Web only | Web only | Web only |
| Validation API | Yes, REST endpoints | Yes | Yes | Yes |
| Language Support | 8 UI languages | Many languages | Many languages | Limited |
| Pricing Model | Free tier + scalable paid plans | Free | Free + paid tiers | Free |
| Privacy Focus | First-party data only | Uses Google data | User privacy oriented | Minimal data |
3. Enforcement and Mitigation Strategies
Once scraping is detected, the policy should specify actions such as:
- Rate limiting: Throttling requests from a given IP or session.
- IP blocking: Temporary or permanent blocks for suspicious sources.
- Challenge escalation: Increasing difficulty or type of CAPTCHA challenges.
- Legal action: Potential pursuit of cease-and-desist or litigation for severe abuse.
This tiered response helps maintain service quality while minimizing false positives.
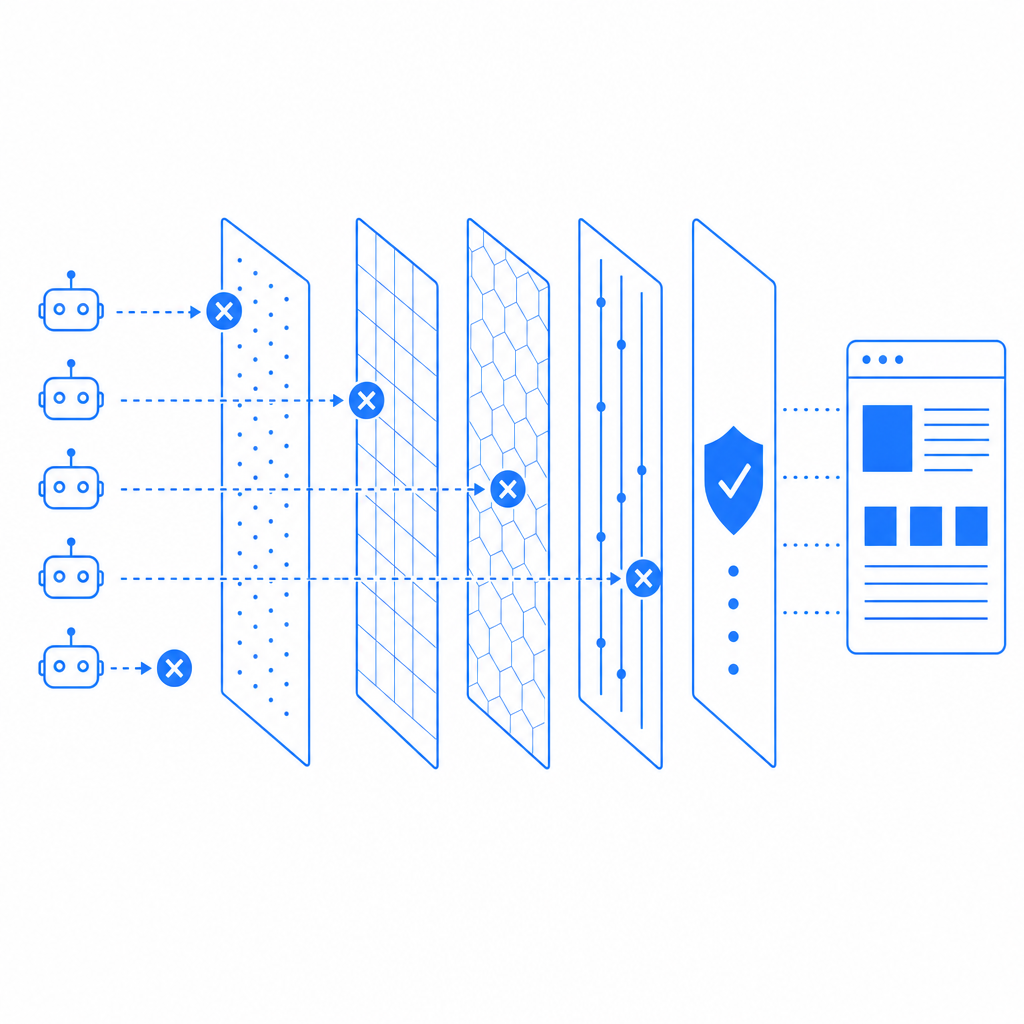
Technical Best Practices to Implement Anti Scraping Policies
Here are key technical aspects to enforce policy parameters effectively:
- Use Progressive Challenges: Start with invisible or low-friction checks and escalate only if suspicious activity continues.
- Integrate Server-Side Validation: Client-side JavaScript challenges can be bypassed unless backed by robust server-side validation of tokens.
- Implement Behavioral Analytics: Combine IP, header, timing, and action analysis to create bot scores, triggering enforcement rules.
- Leverage Device Fingerprinting: Collect non-personal identifiers to distinguish scrapers from legitimate users more accurately.
- Monitor Logs Continuously: Real-time monitoring with alerting helps adapt defenses against evolving scraping tactics.
Below is a simplified example of server-side validation code for CAPTCHA tokens using CaptchaLa’s validation endpoint:
// Example Node.js snippet for server-side CaptchaLa token validation
const axios = require('axios');
async function validateCaptcha(passToken, clientIp) {
const payload = {
pass_token: passToken,
client_ip: clientIp
};
try {
const response = await axios.post(
'https://apiv1.captcha.la/v1/validate',
payload,
{
headers: {
'X-App-Key': 'your-app-key',
'X-App-Secret': 'your-app-secret'
}
}
);
return response.data.success; // true if valid, false otherwise
} catch (error) {
console.error('Captcha validation error:', error);
return false;
}
}Legal and Ethical Considerations in Anti Scraping Policies
While technical defenses are crucial, the policy should also address legal terms:
- Terms of Service (ToS): Clearly state scraping restrictions and consequences.
- Privacy Compliance: Ensure scraping detection and blocking comply with regulations like GDPR when handling user data.
- Fair Use Exceptions: Outline permitted data access by partners or search engines to avoid unfair blocking.
Being transparent in your approach helps with legal protection and maintaining a good reputation among users and partners.
Conclusion
An effective anti scraping policy combines clear definitions, multi-faceted detection and enforcement strategies, legal frameworks, and continuous monitoring. Choosing the right bot defense tools plays a central role. Solutions like CaptchaLa offer comprehensive SDKs, API-based validation, and scalable pricing options that support building adaptive and user-friendly defenses.
Balancing security with user experience is key—excessively aggressive anti scraping can harm genuine visitors, while leniency invites abuse. By implementing an informed policy and leveraging appropriate technical tools, website owners can protect their data and maintain reliable services.
For detailed implementation guidance and pricing plans, explore CaptchaLa’s documentation and pricing page.
Where to go next? Review your current policies and consider integrating bot detection SDKs today. It’s a crucial step toward safeguarding your digital assets against unwanted automated scraping.