
Preventing unwanted data scraping is essential for protecting your website’s content, user information, and business value. Anti data scraping involves techniques to detect and block automated bots that attempt to harvest data at scale without authorization. Rather than relying on a single method, effective anti data scraping combines behavioral analysis, bot detection challenges, IP reputation, and rate limiting to identify and stop scrapers with minimal impact on legitimate users. This article breaks down key strategies you should consider, comparing some popular tools and showing how solutions like CaptchaLa implement them.
Why Anti Data Scraping Matters
Data scraping by bots can lead to various problems:
- Intellectual property theft by copying proprietary content
- Undermining pricing or inventory data for ecommerce sites
- Skewing analytics and degrading user experience through automated abuse
- Leakage of personal user data causing privacy and compliance risks
Effective anti data scraping ensures that your data stays protected against automated extraction while maintaining frictionless access for real users and search engines.
Core Techniques in Anti Data Scraping
Behavioral Analysis and Fingerprinting
Detecting patterns consistent with automated scrapers is often the first line of defense. This can include:
- Monitoring mouse movements, keystrokes, and scrolling
- Analyzing browser fingerprint data, such as installed fonts, plugins, and canvas rendering
- Timing intervals between actions to detect robotic speed or consistency
These signals help determine if the visitor is acting like a human or a scripted bot without upfront user interaction.
Challenge-Response Mechanisms
When suspicion is high, bot defenses escalate to challenge-response tests:
- Traditional CAPTCHAs requiring image or text recognition
- Invisible challenges operating in the background and triggering only when anomalies appear
- More user-friendly methods like Cloudflare Turnstile offering low-friction verification
Such techniques prevent most automated tools from proceeding, especially those relying on headless browsers or direct API calls.
Rate Limiting and IP Reputation
Limiting the frequency of requests per IP or user session helps prevent high-volume scraping. Combining this with IP reputation databases or anomaly detection based on geolocation can proactively block suspicious sources before they consume resources.
JavaScript and Token Validation
Advanced bots may bypass static defenses, so generating session-specific tokens and validating them server-side is key to confirming real users. Solutions like CaptchaLa offer native SDKs supporting Web (JS/Vue/React), mobile platforms, and electron apps, enabling seamless integration of challenge issuance and validation:
// Example: Validate captcha token server-side (Node.js)
// Comments explain key steps
const fetch = require('node-fetch');
async function validateCaptcha(passToken, clientIp) {
const response = await fetch('https://apiv1.captcha.la/v1/validate', {
method: 'POST',
headers: {
'X-App-Key': 'your-app-key',
'X-App-Secret': 'your-app-secret',
'Content-Type': 'application/json',
},
body: JSON.stringify({ pass_token: passToken, client_ip: clientIp }),
});
const result = await response.json();
return result.success; // true if passed validation
}Comparing Popular Anti Data Scraping Tools
Below is a comparison of several well-known CAPTCHA and bot-defense providers regarding ease of integration and anti scraping focus:
| Feature | CaptchaLa | reCAPTCHA | hCaptcha | Cloudflare Turnstile |
|---|---|---|---|---|
| Native SDKs | Web, iOS, Android, Flutter | Web primarily | Web primary | Web primary |
| Languages Supported | 8 UI languages | Multiple | Multiple | Limited |
| Server-side Validation | POST API with token + IP | POST API with token | POST API with token | POST API with token |
| Focus on Anti Data Scraping | Yes, with token + behavior | Primarily spam/bot blocking | Anti-bot with privacy focus | Low-friction bot detection |
| Free Tier | 1000/month | Unlimited | Free tier available | Free |
While reCAPTCHA and hCaptcha are widely used and offer solid bot detection, they may introduce more friction or privacy concerns. Cloudflare Turnstile aims to minimize user friction but requires Cloudflare integration. CaptchaLa balances ease of use across platforms with customizable enforcement for business needs, including anti data scraping specifically.
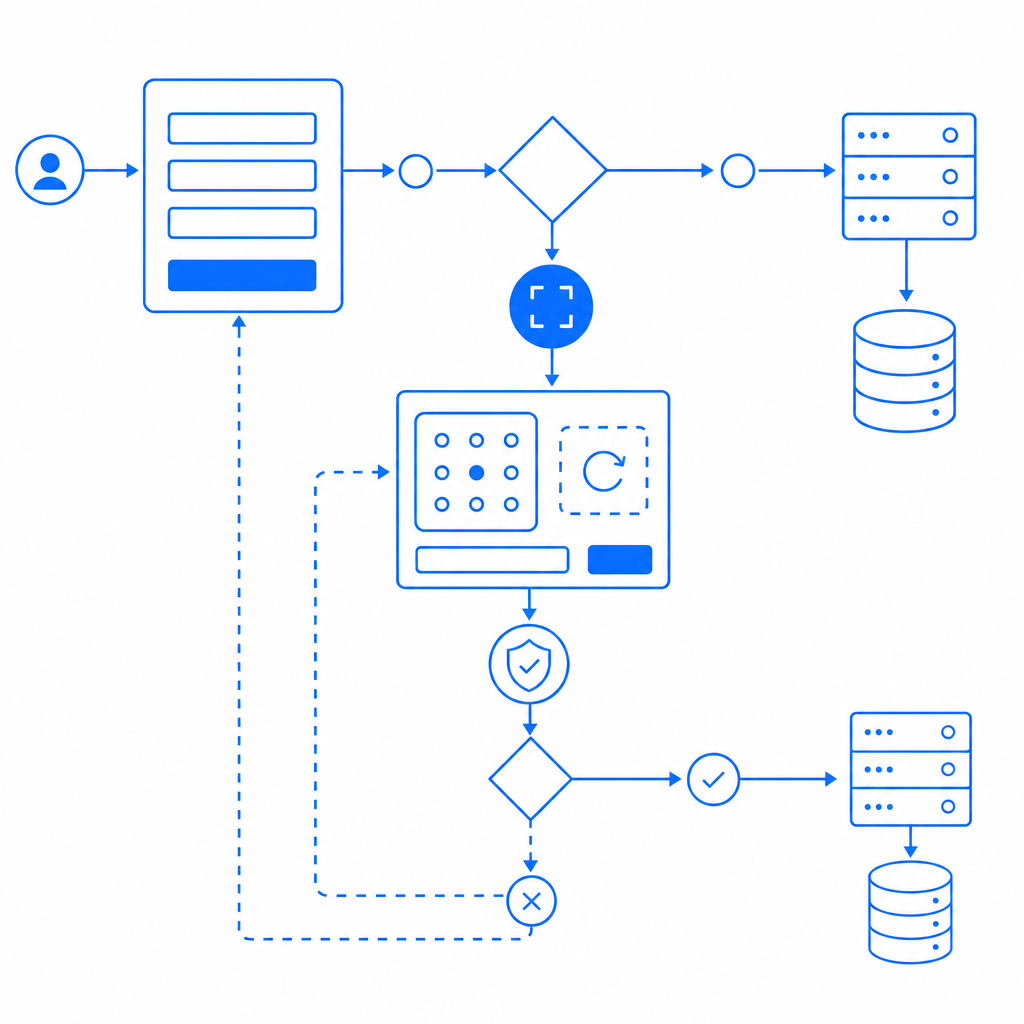
Practical Tips for Implementing Anti Data Scraping
- Evaluate your traffic patterns: Identify unusual spikes or repetitive behavior to prioritize protection points.
- Use layered defenses: Combine fingerprint analysis, rate limiting, and challenge tests rather than relying on one method.
- Adapt challenge difficulty: Escalate verification progressively so legitimate users face minimal disruption.
- Leverage first-party data: Use in-house user signals rather than third-party trackers for privacy compliance.
- Monitor and update: Regularly review logs and update bot signatures or thresholds as scrapers evolve.
Tools like CaptchaLa provide detailed docs and flexible pricing plans suitable for sites ranging from startups to enterprises, making it straightforward to deploy tailored anti data scraping defenses.
Conclusion
Anti data scraping is not just about blocking bots but doing so intelligently to preserve user experience while defending valuable content. Employing multi-layered techniques—behavioral analysis, challenges, rate limits, and token validation—is critical to staying ahead of automated scraping tools that continually evolve. Platforms like CaptchaLa offer robust SDKs and APIs designed from the ground up with anti data scraping in mind, supporting a broad array of web and mobile environments without compromising ease of integration.
Where to go next? Explore CaptchaLa’s pricing page to find a plan that fits your needs or dive into the docs to start integrating comprehensive bot defenses today.