
If you’re looking for anti bot YouTube protection, the short answer is: you need layered defenses that separate real viewers, creators, and API users from automated traffic without making the experience miserable. On a video platform, bots usually show up as fake account creation, comment spam, credential stuffing, scraping of public pages and metadata, and abusive API requests rather than obvious “robot” behavior.
The goal is not to block every automation forever. It’s to raise the cost of abuse, keep friction low for legitimate users, and give your backend enough signal to make a decision. That usually means a mix of challenge flows, risk scoring, rate limits, device and session signals, and server-side validation.
Where bots hit YouTube-style products
A YouTube-like product has a lot of surfaces that attract automation. The obvious ones are login, signup, password reset, comments, uploads, and search. The less obvious ones are watch history endpoints, playlist creation, channel subscription endpoints, and public metadata pages that can be scraped for trend analysis or content harvesting.
Here’s the key pattern: if an endpoint changes state, creates value, or reveals structured data at scale, it will eventually be probed by bots.
Common abuse patterns include:
Mass account creation
- Used for spam, artificial engagement, and reputation laundering.
- Often driven by disposable email domains, rotating IPs, and replayed browser fingerprints.
Credential stuffing
- Attackers try leaked email/password pairs against login forms.
- Usually bursts against a few endpoints with high repetition and low dwell time.
Comment and chat spam
- Focuses on visibility features that are user-generated and immediately public.
- Often combines rapid posting with link injection and keyword stuffing.
Scraping and indexing
- Public video pages, channel pages, and search results are harvested for analytics or republishing.
- Automated clients may mimic normal navigation but ignore rendering, media playback, or session continuity.
API abuse
- Even when your frontend looks clean, a scripted client can hammer backend endpoints directly.
- This is where server-side validation matters most.
For platforms like this, anti bot YouTube protection is less about a single CAPTCHA widget and more about making each suspicious path expensive.
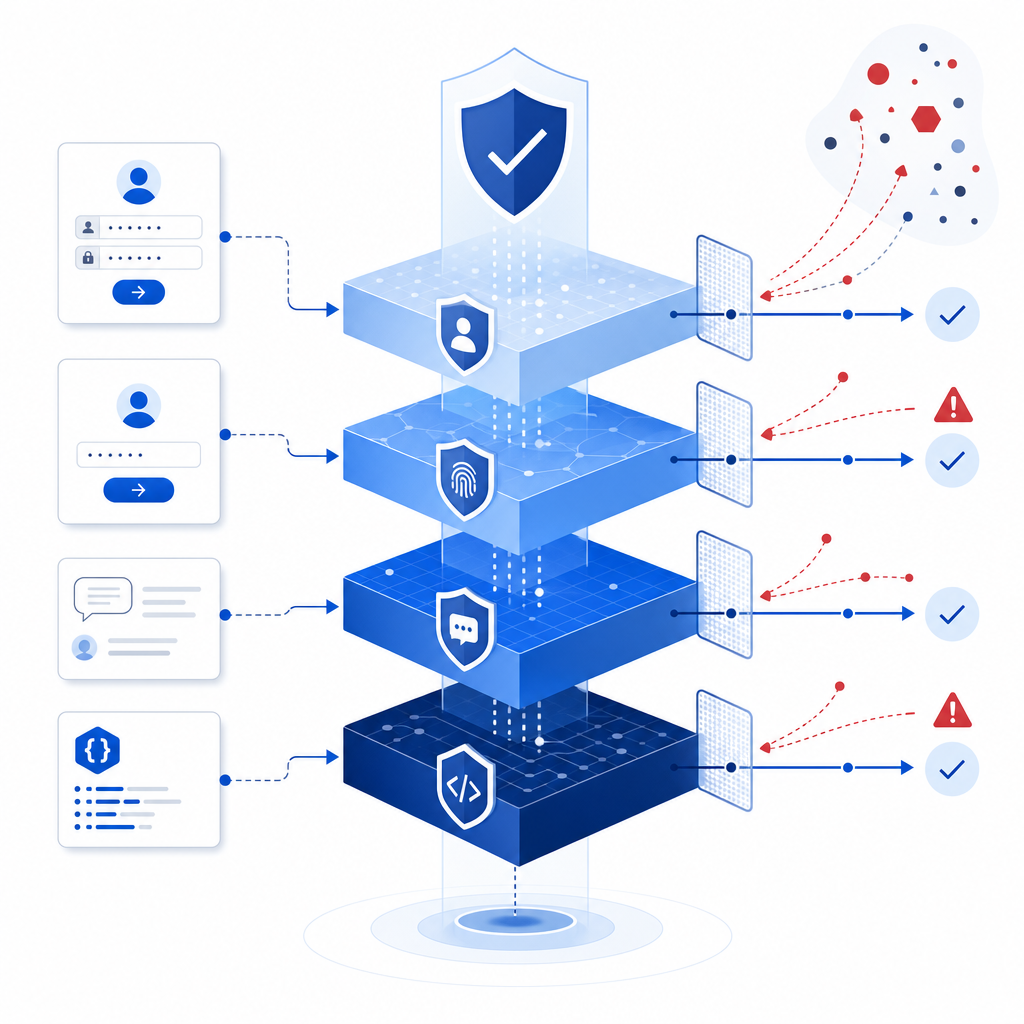
What an effective defense stack looks like
A good bot-defense stack usually has four layers: detection, challenge, validation, and enforcement. Each layer should be able to stand on its own, but they work best together.
1) Detect suspicious behavior early
Start with simple signals you already own:
- request rate per IP, ASN, and account
- session age and consistency
- failed login counts
- device or browser continuity
- time-to-complete on forms
- repeated identical navigation sequences
These signals should feed a risk score, not a hard decision in isolation. A single shared office IP or mobile carrier NAT can look suspicious if you only consider one dimension.
2) Challenge only when needed
This is where CAPTCHA or friction checks come in. The mistake many teams make is showing a challenge to everyone, everywhere. That creates user anger and trains attackers to focus elsewhere.
Instead:
- challenge after unusual velocity
- challenge on high-value actions
- challenge after failed auth attempts
- challenge when the session is inconsistent with past behavior
If you’re comparing options, reCAPTCHA, hCaptcha, and Cloudflare Turnstile all fit into this general category, but they differ in UX, deployment style, and how they fit with your risk model. For a first-party data approach, you may want a system that keeps validation and policy decisions under your control rather than pushing everything to a third party.
3) Validate on the server
Client-side checks alone are not enough. Tokens should be verified on the backend before you allow the action through.
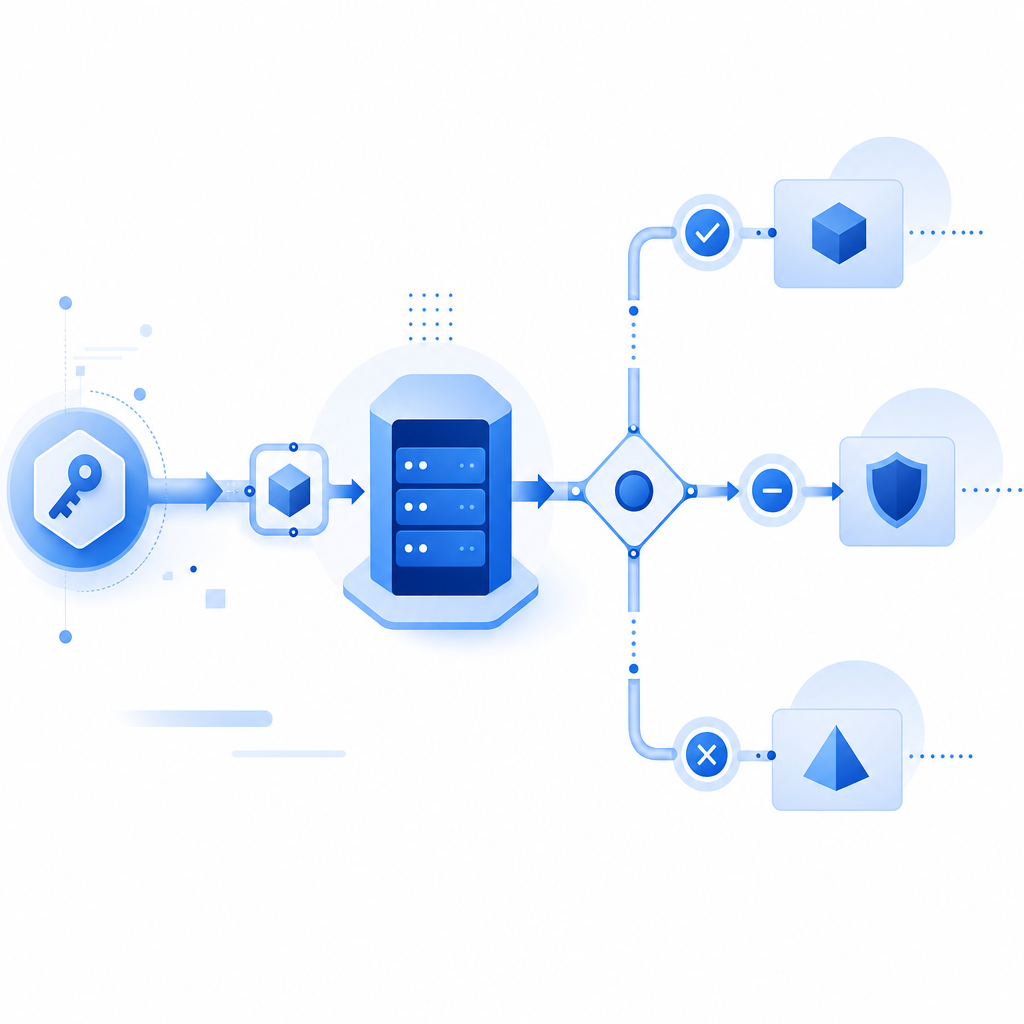
A typical flow looks like this:
1. User or client completes the challenge.
2. Frontend receives a pass token.
3. Frontend sends the pass token with the request.
4. Backend validates the token with the anti-bot service.
5. Backend allows or rejects the action based on the result.For CaptchaLa, validation is done server-side with a POST request to:
https://apiv1.captcha.la/v1/validate
You send:
pass_tokenclient_ip
And authenticate with:
X-App-KeyX-App-Secret
That server-side step is what keeps the challenge from becoming a decorative checkbox. CaptchaLa also supports a server-token issuance flow via:
POST https://apiv1.captcha.la/v1/server/challenge/issue
If you want to integrate across web and mobile, the SDK coverage helps keep the logic consistent: Web JS/Vue/React, iOS, Android, Flutter, and Electron are all supported, with native packages and server SDKs such as captchala-php and captchala-go. It also ships with 8 UI languages, which matters more than people think when your audience is global.
4) Enforce with rate limits and account policies
Even strong bot detection needs backing from operational controls:
- per-IP and per-account rate limits
- temporary lockouts after repeated failures
- comment throttling for new accounts
- upload quotas and reputation gates
- disposable email blocking
- anomaly alerts for spike events
These controls are especially useful when a bot adapts faster than your challenge layer can be tuned. Think of the stack as defense in depth, not a single binary gate.
A practical implementation pattern for product teams
If you’re building or retrofitting anti bot YouTube controls, the cleanest path is to wire challenges only into the operations that matter most.
A practical rollout order:
Protect signup and login first
- These are the highest-leverage abuse points.
- Require validation on repeated failures or suspicious geographies.
Protect comments and chat next
- Add friction for new accounts or high-frequency posting.
- Consider delayed publishing for low-reputation users.
Protect upload and account recovery
- These actions are expensive to undo and attractive to attackers.
- Put tighter thresholds around them.
Harden your public APIs
- Validate tokens on sensitive endpoints.
- Use server-side checks, not only browser state.
Tune by segment
- New users, logged-in creators, and moderators should not all get the same challenge policy.
- Mobile app traffic may deserve different thresholds than browser traffic.
Here’s a simple backend decision sketch:
# English comments only
def allow_action(request):
# Check local abuse signals first
if request.ip_rate > 120:
return deny("rate_limited")
# Require challenge for suspicious sessions
if request.risk_score >= 70:
result = validate_pass_token(
pass_token=request.pass_token,
client_ip=request.client_ip,
app_key=APP_KEY,
app_secret=APP_SECRET,
)
if not result.valid:
return deny("challenge_failed")
# Apply endpoint-specific policy
if request.endpoint == "comment_post" and request.account_age_days < 3:
return delay_or_review()
return allow()That pattern keeps the user experience sane. The majority of users never see a challenge, while suspicious behavior gets pulled into a validation path you can audit.
If you want implementation details, the docs are the right place to map the SDKs and server validation into your stack. And if you’re estimating traffic coverage, the pricing page makes it easy to see where a free 1000/month tier stops and where Pro or Business ranges start.
Choosing among CAPTCHA options without overcomplicating it
Teams often ask whether they should use reCAPTCHA, hCaptcha, Cloudflare Turnstile, or a first-party service. The honest answer is that the right fit depends on your constraints, not on marketing claims.
| Option | Typical strength | Common tradeoff | Good fit for |
|---|---|---|---|
| reCAPTCHA | Broad familiarity | Can feel opaque and adds external dependency | General web forms |
| hCaptcha | Flexible challenge model | More visible friction in some flows | Adjacency to anti-abuse programs |
| Cloudflare Turnstile | Low-friction UX | Best when you already live in Cloudflare’s ecosystem | Cloudflare-centered deployments |
| CaptchaLa | First-party data, server validation, multi-platform SDKs | Requires you to own policy decisions | Teams wanting tighter integration control |
A few practical criteria matter more than brand preference:
- Does the system validate server-side?
- Can you vary policy by endpoint?
- Does it work across web and mobile?
- Can you keep first-party data under your own control?
- Can you operate it without turning every user action into a chore?
For video platforms, the answer often lands on “make verification invisible until risk rises.” That’s the sweet spot.
Final takeaways
Anti bot YouTube protection works best when it treats bot activity as a product problem, not just a security problem. Put challenges on the actions that matter, validate tokens on the backend, and combine that with rate limiting and account policy. The result is less spam, fewer fake accounts, and fewer false positives for real viewers and creators.
If you’re planning a rollout, start with the endpoints that drive the most abuse: signup, login, comments, and API calls. Then expand carefully, using measurable thresholds rather than blanket friction.
Where to go next: review the docs for implementation details, or check pricing if you’re sizing volume for a video platform rollout.