
An anti bot scraper defense is a layered set of checks that identifies automated scraping traffic, raises the cost of abuse, and lets legitimate users through with minimal friction. The practical goal is not to “block all bots” — it’s to distinguish normal browsing from scripted collection, then respond with the lightest effective challenge.
Scraping usually shows up as patterns, not one-off requests: odd request pacing, repeated navigation trees, missing browser behavior, reused sessions, or API calls that look valid at the edge but fail once you inspect context. If you treat every request the same, scrapers win on scale. If you use signals, server-side verification, and adaptive responses, you can make scraping much less economical without punishing real users.
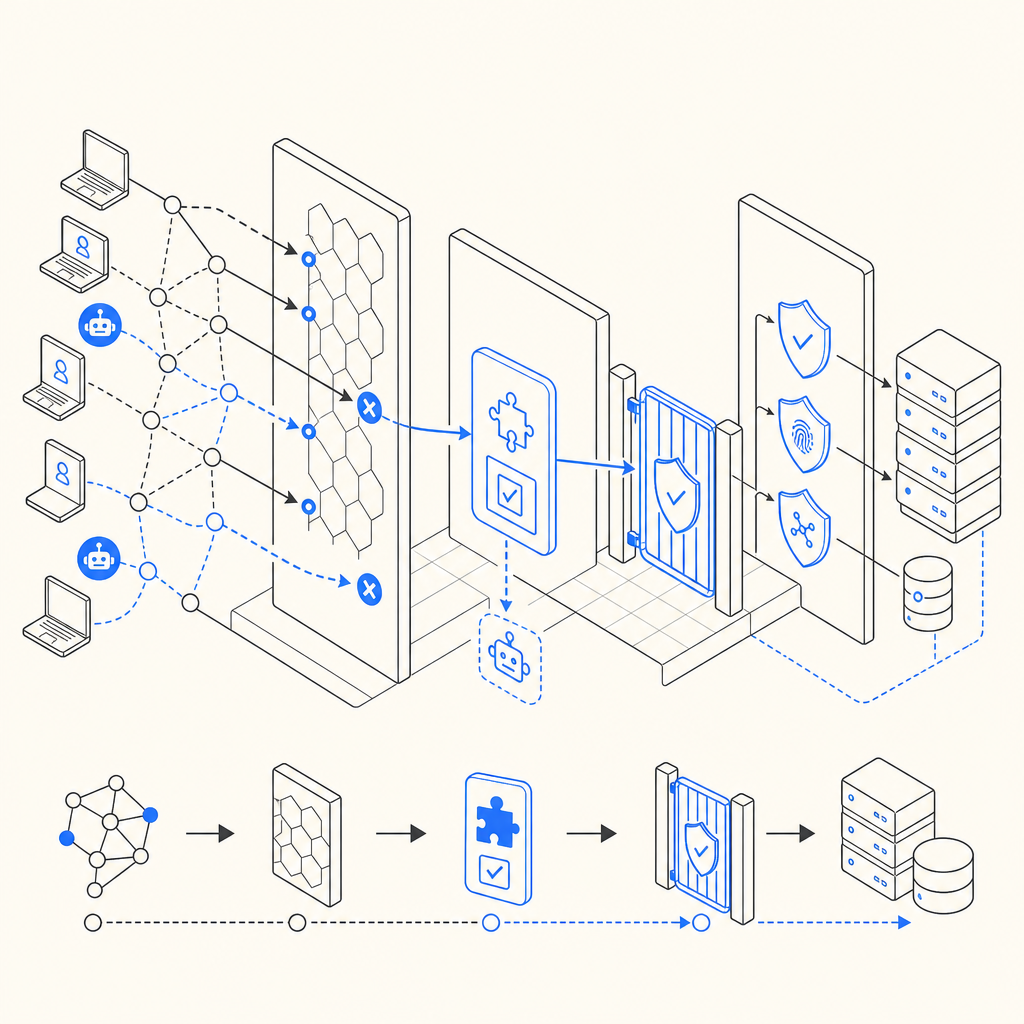
What makes scraper traffic different
A scraper is often optimized for one thing: getting large volumes of content while spending as little time, bandwidth, and money as possible. That means its traffic often has telltale traits:
- Repeated access to structured pages or endpoints.
- High request rates from a small set of IPs, ASN ranges, or device fingerprints.
- Unnatural navigation sequences, like skipping pages that humans typically visit.
- Limited JavaScript execution or inconsistent cookie behavior.
- Session reuse across many accounts or many geographies.
Those signals are rarely enough on their own. A mobile user on poor network conditions can look “bursty,” and privacy tools can reduce fingerprint stability. The trick is to combine signals, not rely on one metric.
A useful mental model is this: an anti bot scraper system should answer three questions quickly:
- Is this traffic behaving like a browser?
- Does the client complete the challenge path correctly?
- Should we allow, challenge, rate-limit, or reject this session?
That flow lets you separate noisy automation from real customers without turning every page into a hurdle.
Detection signals that are worth logging
If you’re building defenses, capture enough context to explain a decision later. Useful fields include:
- Request rate per session, IP, and account
- Path sequence and dwell time between views
- Cookie presence and continuity
- User-agent consistency
- Header ordering and completeness
- JavaScript challenge completion
- Token reuse attempts
- Geo/IP mismatch over time
This is where first-party data matters. You get clearer, more durable signals from your own traffic than from fragile third-party heuristics alone.
A practical defense stack for scraping
The most reliable anti bot scraper strategy is layered. No single control stops everything, but a few controls together reduce abuse sharply.
| Layer | What it does | Typical tradeoff |
|---|---|---|
| Edge rate limits | Slows obvious bursts | Can affect shared networks |
| Fingerprint/session checks | Identifies repeated automation | Needs tuning |
| JavaScript challenge | Verifies browser execution | Slight client overhead |
| Token validation | Confirms challenge completion server-side | Requires backend integration |
| Behavioral scoring | Adapts to risk level | Needs ongoing calibration |
Here is a simple implementation pattern:
# English comments only
1. Receive request
2. Check rate and session history
3. If risk is low, allow normally
4. If risk is medium, issue a browser challenge
5. If challenge passes, send a short-lived token
6. Validate token on the server before trusting the action
7. If risk is high, block or require stronger verificationThat pattern works because it does not depend on one brittle signal. It also separates client-side proof from server-side trust. A scraper may mimic UI clicks, but it should still fail if it cannot complete the full validation path.
If you use CaptchaLa, that same split is built into the flow: the client receives a challenge, then your backend validates the pass token with a server call. The validation endpoint is straightforward: POST https://apiv1.captcha.la/v1/validate with {pass_token, client_ip} and your X-App-Key plus X-App-Secret. For server-generated challenge issuance, there is also POST https://apiv1.captcha.la/v1/server/challenge/issue.
Choosing the right challenge level
Not every endpoint deserves the same friction. A public marketing page, a search endpoint, and a checkout flow have different abuse profiles. The smarter move is to assign defenses by risk.
Example policy by endpoint
Public content pages
Use lightweight checks and monitor for bulk access patterns.Search, pricing, and catalog endpoints
Add rate limits, token checks, and behavior scoring.Sign-up, login, password reset
Use stronger challenges and stricter replay protection.Sensitive actions and high-value APIs
Require server validation, device continuity, and tighter session controls.
This is where modern CAPTCHA providers differ in approach. reCAPTCHA, hCaptcha, and Cloudflare Turnstile all focus on balancing friction and verification, but their implementation details and privacy posture differ. For teams that want a product with broad platform coverage and first-party data handling, it helps to evaluate the exact trust model rather than just the challenge widget.
CaptchaLa’s product surface is fairly broad: 8 UI languages, native SDKs for Web (JS/Vue/React), iOS, Android, Flutter, and Electron, plus server SDKs like captchala-php and captchala-go. That matters when your traffic spans browser, mobile, and desktop clients. You want the same validation logic across channels, not a patchwork of different bots checks.
Instrumentation and response: what to do when abuse spikes
Detection is useful only if the response is proportional. A good anti bot scraper program usually has several response modes:
- Passive logging for low-risk anomalies
- Soft challenge for uncertain traffic
- Temporary throttling for repeated suspicious behavior
- Hard block for confirmed automation or abuse
- Escalation to account review for repeat offenders
The key is to avoid overreacting to a single anomaly. For example, a legitimate user might trigger a challenge after an IP change and a fast sequence of views. If they pass, record that success and lower future friction for a while.
A simple operational checklist can help:
- Track baseline traffic by route, region, and time of day.
- Define what “normal” looks like for each high-value endpoint.
- Alert on sudden spikes in request density or token failures.
- Correlate failures with IP reputation, session reuse, and path repetition.
- Review false positives weekly and adjust thresholds.
- Keep challenge logic short-lived and server-verified.
If you want to inspect the integration details more closely, the docs are the best place to start. They show the validate flow, the loader script at https://cdn.captcha-cdn.net/captchala-loader.js, and the platform-specific SDKs. For teams evaluating cost, the pricing page is useful too: there’s a free tier at 1000 validations per month, Pro at 50K–200K, and Business at 1M, which helps when you’re sizing defenses to actual traffic.
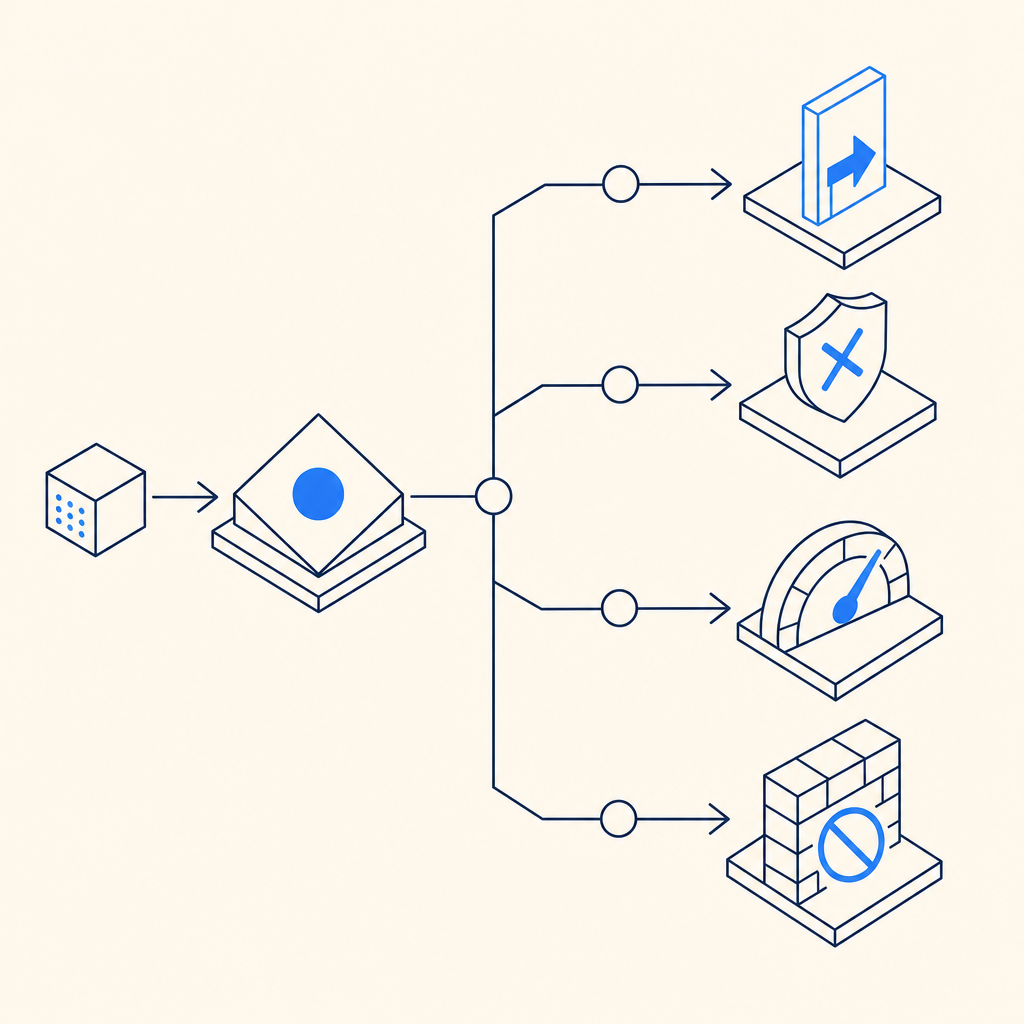
What good looks like over time
The strongest scraper defense programs evolve. Scrapers adapt, traffic patterns change, and product flows get redesigned. So the goal is not a one-time lock; it’s an operating loop.
A healthy loop looks like this:
- Collect signals at the edge and in your app.
- Validate challenge results on the server.
- Use per-route policies instead of a single global rule.
- Review false positives and tune thresholds.
- Keep an eye on replay attempts and token misuse.
- Re-test after major frontend or API changes.
If you do that, your anti bot scraper strategy becomes less about fighting every new script and more about controlling trust. That’s a much better place to be, because it reduces abuse while keeping legitimate users moving.
Where to go next: if you’re planning implementation, start with the docs, or compare tiers on the pricing page.