
An anti bot mechanism is a layer that distinguishes legitimate human traffic from automated requests, then blocks, challenges, or scores suspicious activity before it can harm your app. Done well, it reduces signup abuse, credential stuffing, scraping, and fake transactions without turning every user into a puzzle-solver.
That sounds simple, but the useful part is in the details: modern bot defense is usually a mix of client-side signals, server-side validation, session context, and risk-based decisions. If you’re designing one yourself or evaluating a vendor, the goal is not “stop all bots” — that’s unrealistic — but to make abuse expensive, unreliable, and easy to detect.
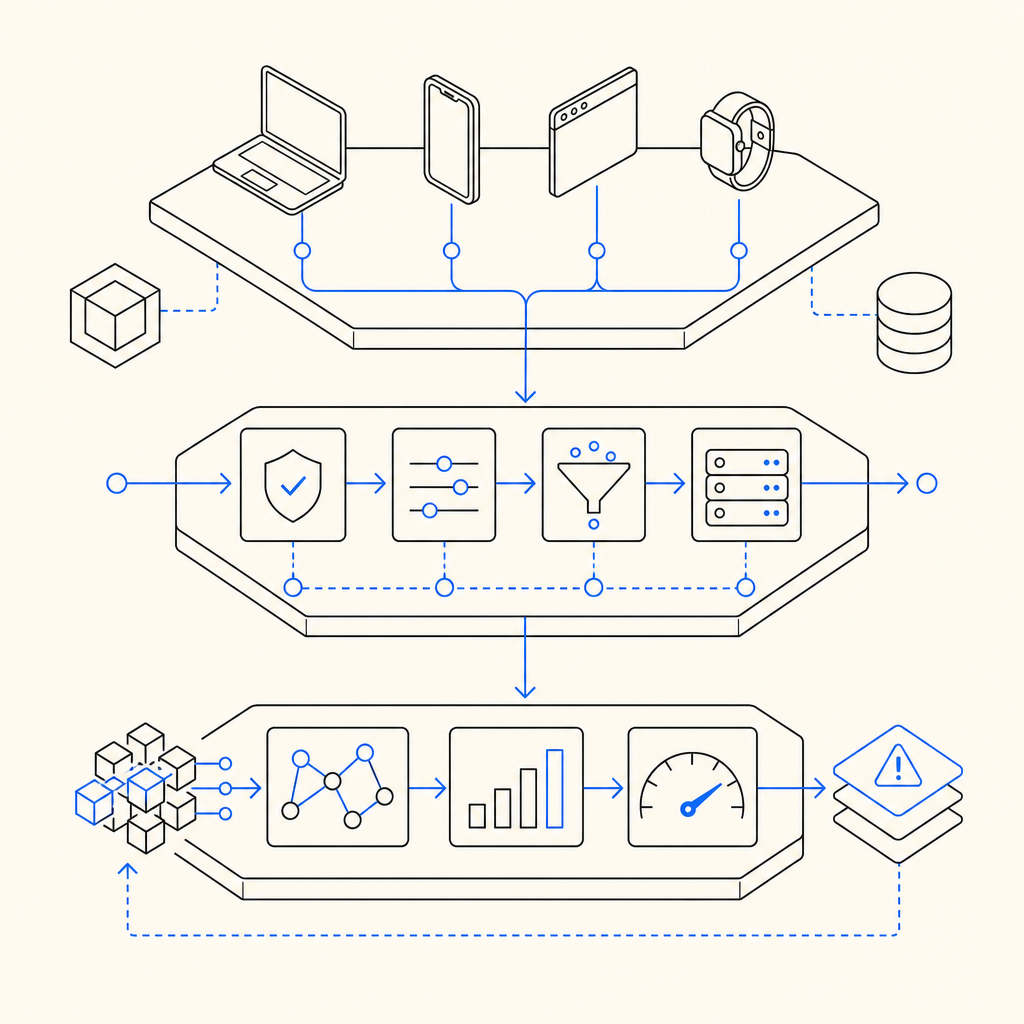
What an anti bot mechanism actually does
At a high level, an anti bot mechanism answers three questions:
- Is this request coming from the browser, app, or automation?
- Does the interaction look consistent with a real session?
- What action should the server take if the answer is uncertain?
The most familiar form is a challenge. Some systems use checkbox or image tasks; others lean on invisible checks, device fingerprints, or browser integrity signals. More advanced setups combine multiple checks:
- JavaScript execution and timing
- Client fingerprint stability
- IP reputation and geo consistency
- Rate patterns per account, device, or subnet
- Session continuity across pages and forms
- Server-side token validation
The important architectural point is that the client should not be the final authority. A client can collect signals, but the server should verify the result before accepting a sensitive action. That is why a clean validation flow matters.
For example, CaptchaLa exposes a straightforward validation endpoint:
POST https://apiv1.captcha.la/v1/validate
Headers:
X-App-Key: your_app_key
X-App-Secret: your_app_secret
Body:
{
"pass_token": "...",
"client_ip": "203.0.113.42"
}That pattern keeps the decision on the backend, where it belongs.
The main approaches, compared
Not every anti bot mechanism is trying to solve the same problem. A checkout flow, a login form, and a public API need different thresholds and UX tradeoffs.
| Approach | What it checks | Strengths | Tradeoffs |
|---|---|---|---|
| Visual challenge | User interaction with a task | Familiar, easy to explain | Can frustrate real users |
| Invisible risk scoring | Device/session signals | Low friction, fast | Needs careful tuning |
| Token validation | Signed proof from client to server | Simple backend integration | Depends on token hygiene |
| Rate limiting | Request volume and patterns | Great for brute-force and scraping | Not enough on its own |
| Behavior analysis | Timing, navigation, interaction patterns | Useful for abuse detection | More complex to implement |
Popular third-party options like reCAPTCHA, hCaptcha, and Cloudflare Turnstile all fit into this broader space, but they differ in UX style, data handling, and integration model. The right choice usually depends on whether you need a visible challenge, a mostly invisible check, or a hybrid approach.
If you want a lighter integration path, CaptchaLa provides native SDKs for Web (JS, Vue, React), iOS, Android, Flutter, and Electron, plus server SDKs for PHP and Go. It also supports 8 UI languages, which matters if you serve a global audience and want the fallback experience to stay understandable.
What a robust flow looks like
A secure anti bot mechanism typically follows a chain like this:
- The client loads a loader script and initializes the widget or risk check.
- The client receives a short-lived token after passing the challenge or heuristic check.
- The application sends that token to the server alongside request context.
- The server validates the token with the provider.
- The app allows, denies, or escalates the action based on the validation result and local policy.
Here’s the defender’s version of the flow in a compact sketch:
// Client: capture a proof token after the challenge succeeds
const token = await captcha.getPassToken()
// Server: verify the token before allowing a sensitive action
const response = await fetch('https://apiv1.captcha.la/v1/validate', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'X-App-Key': process.env.APP_KEY,
'X-App-Secret': process.env.APP_SECRET
},
body: JSON.stringify({
pass_token: token,
client_ip: req.ip
})
})
// English-only comments above explain the integration pointsFor some workflows, you may also issue a server token first, using:
POST https://apiv1.captcha.la/v1/server/challenge/issueThat can be useful when your backend wants to control challenge issuance based on its own policy, not just the client’s page state.
The loader itself is served from:
https://cdn.captcha-cdn.net/captchala-loader.jsThat detail sounds minor, but it matters operationally: a stable loader endpoint helps keep integration consistent across web properties and apps.
Where these checks help most
Anti bot mechanisms are especially valuable for:
- account creation
- password reset abuse
- login abuse and credential stuffing
- ticketing or checkout fraud
- comment spam and form abuse
- scraping of pricing, inventory, or content
- abuse of free trials or promo codes
If your business relies on first-party interaction data, the mechanism should respect that boundary. CaptchaLa’s model is built around first-party data only, which is relevant for teams that want tighter control over what gets collected and how it’s used.
Choosing the right balance of friction
A common mistake is assuming stricter always means safer. In practice, over-aggressive bot defense can create more support tickets, more abandoned carts, and more false positives than it prevents.
A better approach is to tune by risk:
- Low-risk actions: passive checks, score-based decisions, no visible challenge
- Medium-risk actions: lightweight challenge or step-up verification
- High-risk actions: strong validation plus rate limiting and server-side checks
That layered design also makes fallback behavior easier. If one signal is noisy, another can carry the decision. If a user is on a corporate network or privacy-protected environment, the system can still rely on token validation, session continuity, and behavior patterns instead of a single brittle fingerprint.
A few practical rules help keep the UX sane:
- Don’t challenge every request; challenge when risk crosses a threshold.
- Keep token lifetimes short enough to reduce replay risk.
- Pair bot defense with rate limiting and account-level anomaly detection.
- Log validation outcomes so you can measure false positives.
- Test flows on slow networks and mobile devices, where timing can differ.
CaptchaLa’s published tiers may help when estimating rollout cost: there’s a free tier at 1,000 validations per month, Pro plans in the 50K–200K range, and Business at 1M. That’s not the main reason to pick a mechanism, but it helps when you’re planning traffic growth and multiple environments.
Implementation notes for engineers
If you’re wiring this into a real application, a few specifics are worth planning up front:
- Where validation happens: always on the server for sensitive actions.
- What you log: token status, request path, IP, and outcome.
- What you compare: current IP, session state, and request timing.
- What you protect first: logins, signups, password resets, and checkout.
- What you monitor: challenge rate, pass rate, and conversion impact.
For teams using Java, mobile, or cross-platform stacks, SDK availability can shorten rollout time. CaptchaLa publishes Maven coordinates la.captcha:captchala:1.0.2, CocoaPods Captchala 1.0.2, and captchala 1.3.2 on pub.dev, which can help if your app spans web and native clients.
In practice, the best anti bot mechanism is the one that fits your threat model, not the one with the most moving parts. If you mainly fight spammy form submissions, a lightweight token check plus server-side validation may be enough. If you’re defending login or payment flows, you’ll usually want layered controls and tighter policy decisions.
Where to go next: if you’re comparing approaches or planning an integration, the docs are the fastest place to see the flow end-to-end, and pricing is useful for estimating volume as traffic grows.