
If you’re looking for an anti bot f5 approach, the short answer is: use layered detection, challenge only when risk is high, and make validation happen on the server. That combination stops a lot of automation without turning every visitor into a puzzle solver.
“F5” usually shows up in conversations about web traffic protection, especially when teams are comparing control points across load balancers, edge defenses, and application-layer checks. The important part is not the label; it’s the architecture. A good anti-bot stack should identify suspicious behavior early, challenge selectively, and verify the result with a trusted backend. That keeps bots from draining login forms, signup flows, inventory checks, or ticketing endpoints while preserving a smooth path for real users.
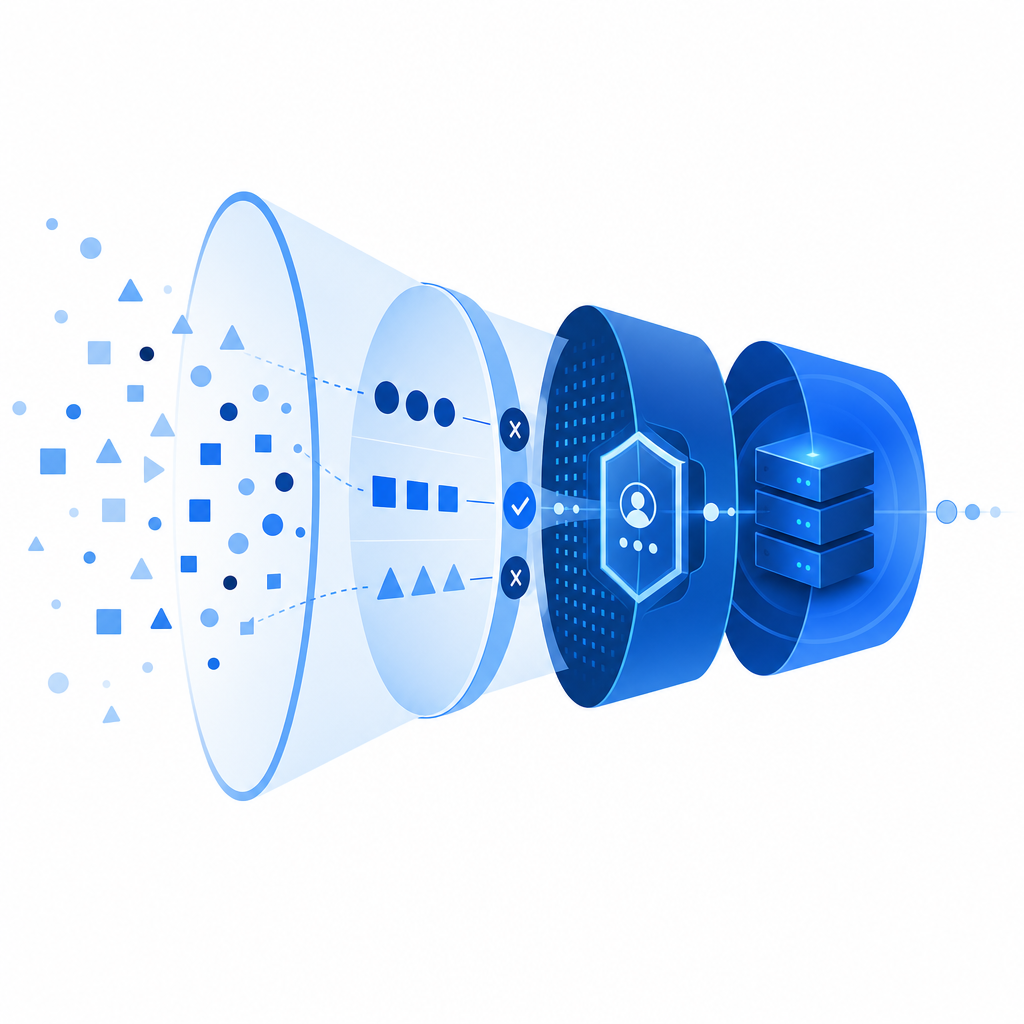
What anti bot f5 usually means in practice
At a practical level, anti bot f5 is about controlling automated traffic close to the application entry point, then confirming legitimacy with server-side validation. The goal is to avoid relying on one signal alone.
A strong implementation usually combines these elements:
Request classification
- IP reputation
- request rate and burst patterns
- header consistency
- session continuity
- device/browser anomalies
Progressive challenge
- low-friction challenge for suspicious-but-not-certain traffic
- stronger challenge for repeated abuse
- no challenge for trusted users when risk is low
Server-side verification
- never trust a client-only pass
- validate tokens on your backend
- bind challenge results to your app’s session and context
Telemetry and tuning
- track false positives
- monitor challenge completion rates
- segment by endpoint, country, and device class
The key idea is simple: detection happens at the edge, but trust is established on the server. That separation prevents most trivial automation from replaying or faking a successful challenge.
Why client-only checks are not enough
Client-side defenses can help, but they’re easy to overestimate. If your app only checks whether a widget loaded or a script executed, an attacker can often mimic that signal. What you really want is proof that a challenge was completed in your application context and validated by your backend.
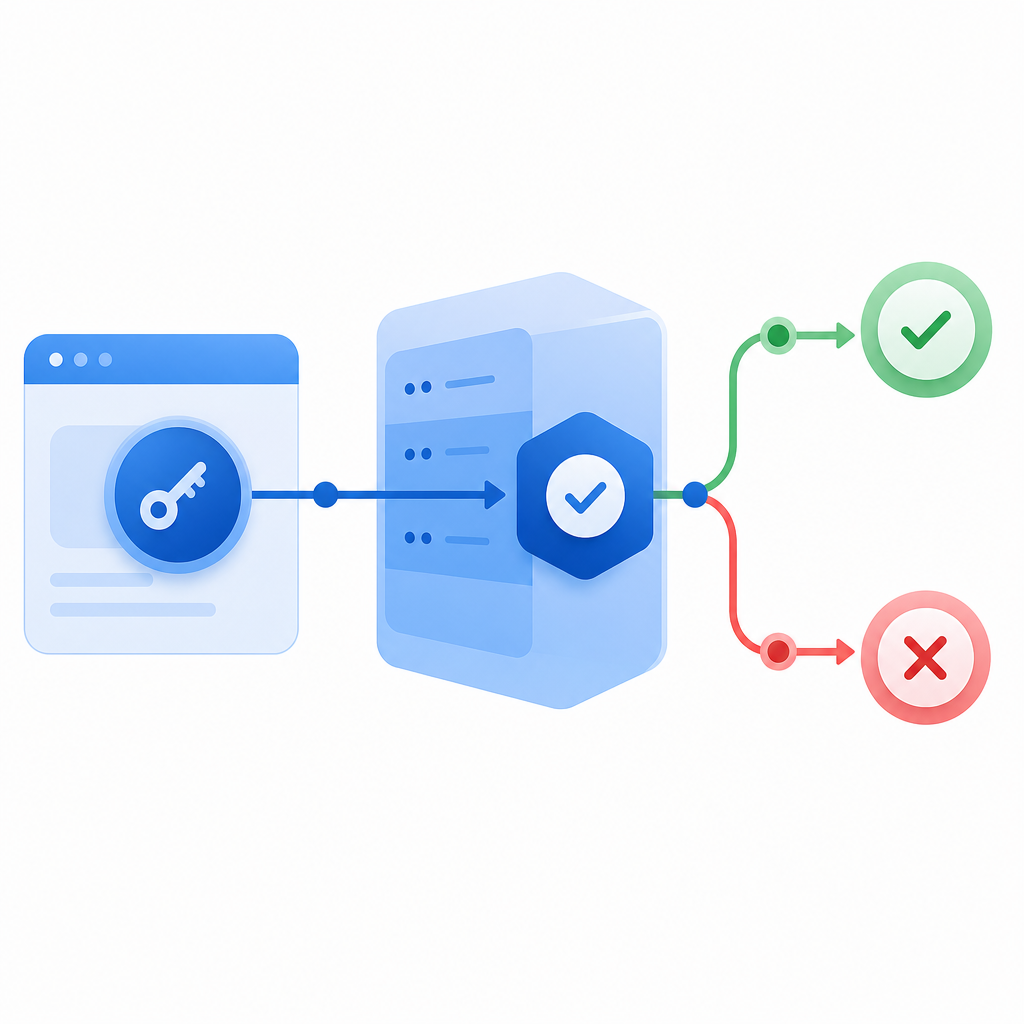
A server-verified flow typically looks like this:
- the browser loads a challenge widget or loader
- the user completes the interaction
- the client receives a pass token
- your server validates that token before accepting the action
For example, CaptchaLa exposes a loader at https://cdn.captcha-cdn.net/captchala-loader.js and a validation endpoint at POST https://apiv1.captcha.la/v1/validate. The validation request includes pass_token and client_ip, authenticated with X-App-Key and X-App-Secret. That means your application can verify the challenge result before creating an account, sending an OTP, placing an order, or exposing a sensitive workflow.
Here’s the point: if the server does not validate, the challenge is mostly decorative. A bot operator only needs to emulate the browser well enough to get past the front end. Server validation raises the bar substantially.
A practical defender’s playbook
If you’re building or reviewing anti-bot protection, this checklist is a good place to start.
1) Protect the highest-value endpoints first
Not every page deserves the same scrutiny. Focus on flows that attract automation:
- account creation
- login and password reset
- checkout and inventory checks
- OTP and SMS request forms
- scraping-sensitive search endpoints
- promo code, referral, or coupon submissions
These are the endpoints where bot activity causes real cost: fraud, abuse, resource drain, and user frustration.
2) Use friction only when risk justifies it
A challenge on every request can hurt conversion. Better systems use risk scoring and selective challenge placement. For example:
- first request from a new session: low friction
- repeated requests in a short burst: challenge
- same IP hitting multiple accounts: stronger challenge
- known good user/device: no challenge
This approach is especially useful for globally distributed audiences, where network quality and device diversity are wide. CaptchaLa supports 8 UI languages, which helps reduce unnecessary friction for international traffic.
3) Validate on the backend, not just in JavaScript
A clean implementation should send the pass token to your server, then call the validation endpoint before allowing the action. Pseudocode helps illustrate the flow:
// Client side:
// 1. Render challenge
// 2. Receive pass token
// 3. Send token to backend with action request
// Server side:
// 1. Receive pass token and client IP
// 2. POST to validation endpoint
// 3. Allow action only if validation succeeds
// 4. Log outcome for abuse monitoringIf you want a stricter pattern, use a short-lived server token as part of the challenge issuance flow. CaptchaLa also provides a server-token endpoint at POST https://apiv1.captcha.la/v1/server/challenge/issue, which is useful when your backend needs to initiate or control issuance rather than relying only on front-end triggers.
4) Measure false positives early
A defense that stops bots but blocks real users is expensive. Watch for:
- challenge abandonment rate
- login completion drop-off
- checkout conversion changes
- regional latency differences
- accessibility complaints
If a particular segment gets challenged too often, adjust thresholds or exempt trusted flows. The best anti bot f5 strategy is one you can tune, not one you deploy once and forget.
How CaptchaLa fits into a modern stack
Different teams need different integration points. Some want a lightweight web widget. Others need SDKs for mobile and desktop apps. CaptchaLa covers both, with native SDKs for Web (JS, Vue, React), iOS, Android, Flutter, and Electron. For backend integration, there are server SDKs for captchala-php and captchala-go, which makes it easier to keep validation logic close to your application code.
That matters because anti-bot controls should live where the abuse happens. If the attack is hitting a web form, use the web SDK. If it’s hitting a mobile flow, validate there too. If your backend is PHP or Go, server-side SDKs reduce integration mistakes and make enforcement more consistent.
CaptchaLa’s pricing structure is also straightforward for teams testing the waters: a free tier at 1000 validations per month, Pro in the 50K–200K range, and Business at 1M. For teams evaluating options, it’s worth comparing implementation style and validation flow alongside familiar tools like reCAPTCHA, hCaptcha, and Cloudflare Turnstile. Those services each have their own trade-offs around user experience, policy, and deployment model. The right choice depends on your application, not on a generic benchmark.
For setup details, the docs are the best next stop, and the pricing page helps if you’re estimating volume.
Common mistakes that weaken anti-bot controls
Even strong teams make a few predictable mistakes:
Trusting the challenge result in the browser only
- This is the most common mistake.
- Always verify server-side.
Applying one policy to every endpoint
- Signup and checkout need different thresholds than marketing pages.
Logging too little
- Without request context, it’s hard to tune detection or investigate abuse.
Ignoring session binding
- A token should be useful only for the intended session and action.
Over-challenging legitimate users
- If you see sharp abandonment spikes, your thresholds may be too aggressive.
The best defenses behave more like traffic controllers than gatekeepers. They inspect, route, and verify instead of reflexively blocking everything.
Closing thought
Anti bot f5 works best when it’s treated as a layered control system: classify traffic, challenge selectively, and verify on the server before the action is allowed. That model reduces bot abuse without making your real users pay the price.
Where to go next: read the docs for integration details, or compare plans on pricing if you’re estimating validation volume.