
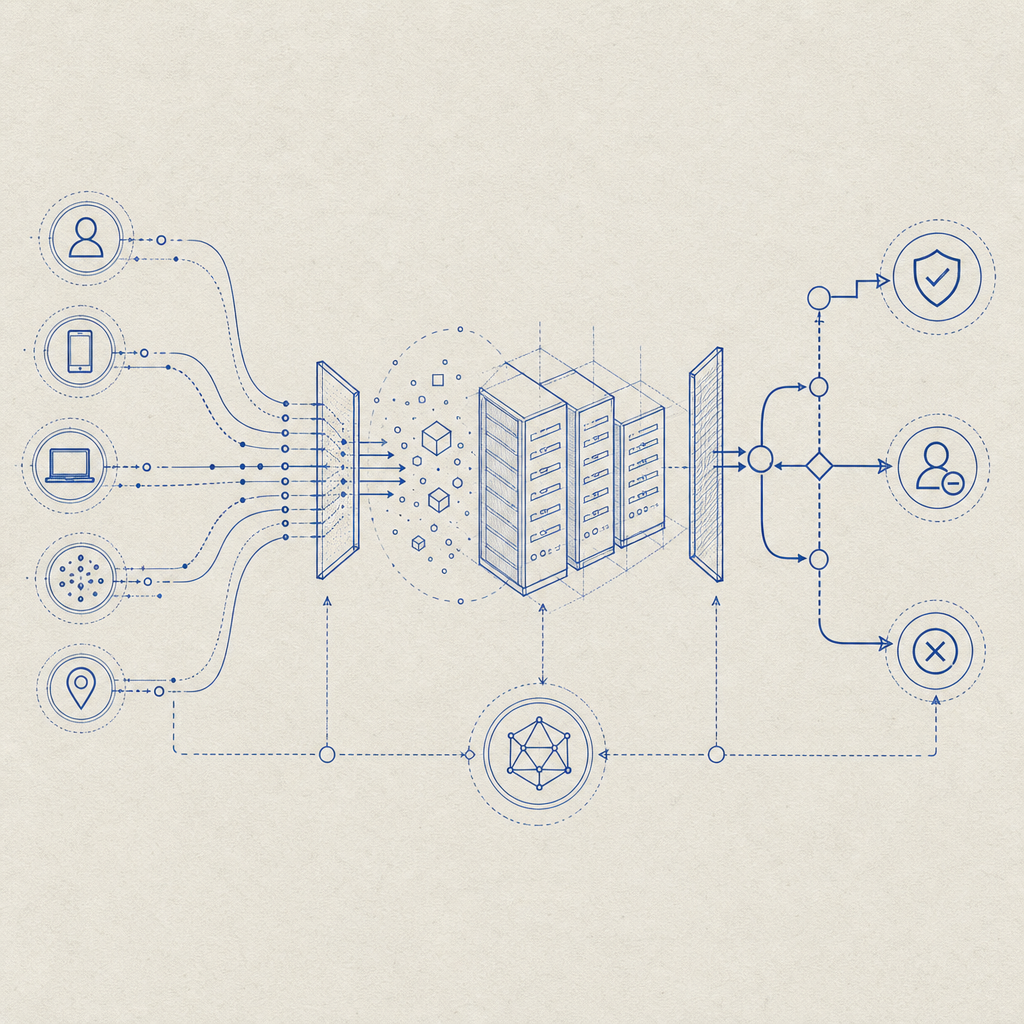
A bot detector is not just a checkbox for stopping spam; it’s a layered decision system that scores behavior, verifies challenge completion, and helps you decide when to allow, challenge, or block a request. The real question behind any bot detector essay is simple: what signals are strong enough to trust without punishing legitimate users?
Good detection starts by treating bots as a moving target. Simple IP filters and static rules can catch noisy abuse, but they miss distributed attacks, headless automation, and replayed session flows. Stronger defenses combine client-side signals, server-side verification, and rate-aware policy decisions. That balance matters because the cheapest bot to stop is the one you identify early, before it can enumerate accounts, scrape content, or drain signup funnels.
What a bot detector essay should really cover
A useful essay about bot detection should explain mechanics, not just outcomes. If you only say “bots are bad,” you miss the part that matters to engineers: how a detector distinguishes a real browser from scripted traffic, and how it avoids false positives.
At a high level, bot detection usually combines:
Client integrity signals
Browser runtime behavior, JavaScript execution success, and interaction consistency. These are useful because many automation stacks are brittle when they have to behave like human users across real pages.Challenge completion
A challenge can prove a session had enough friction to discourage mass abuse. The point is not to make access impossible; it’s to make abuse expensive.Server-side validation
A token should be checked on your backend, not trusted just because the client says it passed. This is where many implementations become weak: they collect a token but never verify it against their own policy engine.Context-aware policy
The same event may be normal for one user and suspicious for another. Signup, login, password reset, checkout, and content posting deserve different thresholds.
If you’re writing or reading a bot detector essay, ask whether it explains the full loop: signal collection, challenge issuance, server validation, and enforcement. Anything less is usually just marketing prose with a technical coat of paint.
Comparing common approaches
Different services solve different parts of the problem. reCAPTCHA, hCaptcha, and Cloudflare Turnstile are all widely used, but they don’t fit every architecture the same way. The right choice often depends on your UX tolerance, privacy constraints, and backend workflow.
| Approach | Strengths | Trade-offs | Typical fit |
|---|---|---|---|
| reCAPTCHA | Familiar, broadly recognized, easy to find examples | Can add noticeable friction depending on mode | General web forms |
| hCaptcha | Solid challenge flow, often chosen for abuse-prone flows | User experience can vary with challenge difficulty | Signups, login protection |
| Cloudflare Turnstile | Low-friction verification, simple deployment for Cloudflare users | Best fit if your stack already uses Cloudflare controls | Edge-aware deployments |
| Custom bot detector | Tailored logic, full control over signals and policy | More engineering work to maintain and tune | High-risk workflows, internal tooling |
| CaptchaLa | Multi-platform support, first-party data model, clear server validation flow | Requires thoughtful integration like any security control | Web, mobile, and app-centric products |
A pragmatic takeaway: don’t choose based on the loudest promise. Choose based on how the detector integrates with your risk model and how much control you need over validation. If you need a single service across web, mobile, and desktop apps, CaptchaLa is worth a look because it supports native SDKs for Web (JS/Vue/React), iOS, Android, Flutter, and Electron, plus server SDKs like captchala-php and captchala-go.
Signals, validation, and the backend trust boundary
The most important part of a bot detector essay is the trust boundary. A client can request a challenge, display a widget, or receive a pass token, but your backend must still make the final decision.
That usually looks like this:
Client requests challenge
Client completes challenge
Client receives pass token
Backend validates token
Backend applies policy
Backend allows, challenges again, or blocksFor CaptchaLa, the validation endpoint is POST https://apiv1.captcha.la/v1/validate, with a body that includes pass_token and client_ip, plus X-App-Key and X-App-Secret headers. There’s also a server-token flow at POST https://apiv1.captcha.la/v1/server/challenge/issue for cases where your backend needs to create or coordinate challenge issuance directly.
That split matters because it keeps your security logic on your side of the fence. The token is evidence, not a verdict. If you skip server validation, you’re trusting the browser to tell you it behaved well, which is not a security model so much as wishful thinking.
First-party data and privacy-conscious design
Another reason modern bot detection is changing is the data pipeline. Many teams want to avoid third-party data sharing and opaque enrichment. CaptchaLa’s model uses first-party data only, which helps teams keep their verification workflow aligned with their own application boundaries.
That’s not just a privacy talking point. It also simplifies compliance reviews and makes it easier to reason about what data is collected, where it goes, and why it exists. When your fraud and abuse controls are embedded in product flows, predictability is a feature.
Deployment details that separate prototypes from production
A detector becomes useful only when it’s actually deployed everywhere the abuse happens. That means web, mobile, desktop, and API-backed flows need a consistent strategy. In practice, the details matter more than the headline.
Here’s a short checklist for production use:
Ship the loader consistently
For web flows, the loader ishttps://cdn.captcha-cdn.net/captchala-loader.js. Load it where the challenge is needed, not globally everywhere if you don’t have to.Verify every pass token server-side
Sendpass_tokenandclient_ipto your backend validation endpoint, and store the outcome with request metadata for later analysis.Use different policies by route
Login should not use the same threshold as newsletter signup or checkout.Instrument false positives
Track user drop-off, retry rates, and regional patterns. A detector that blocks abuse but breaks conversions is still a problem.Document platform support
CaptchaLa has 8 UI languages and SDKs for JavaScript, Vue, React, iOS, Android, Flutter, and Electron. For package managers, it also publishesla.captcha:captchala:1.0.2for Maven,Captchala 1.0.2for CocoaPods, andcaptchala 1.3.2on pub.dev.Match plan size to traffic reality
CaptchaLa’s free tier covers 1000 requests per month, Pro covers roughly 50K–200K, and Business targets 1M. That makes it easier to start small and scale without redesigning the integration.
A good bot detector essay should make one practical point very clear: implementation quality matters more than brand names. A service with the right API flow, backend validation, and platform coverage will outperform a “smart” detector that’s only partially wired into your stack.
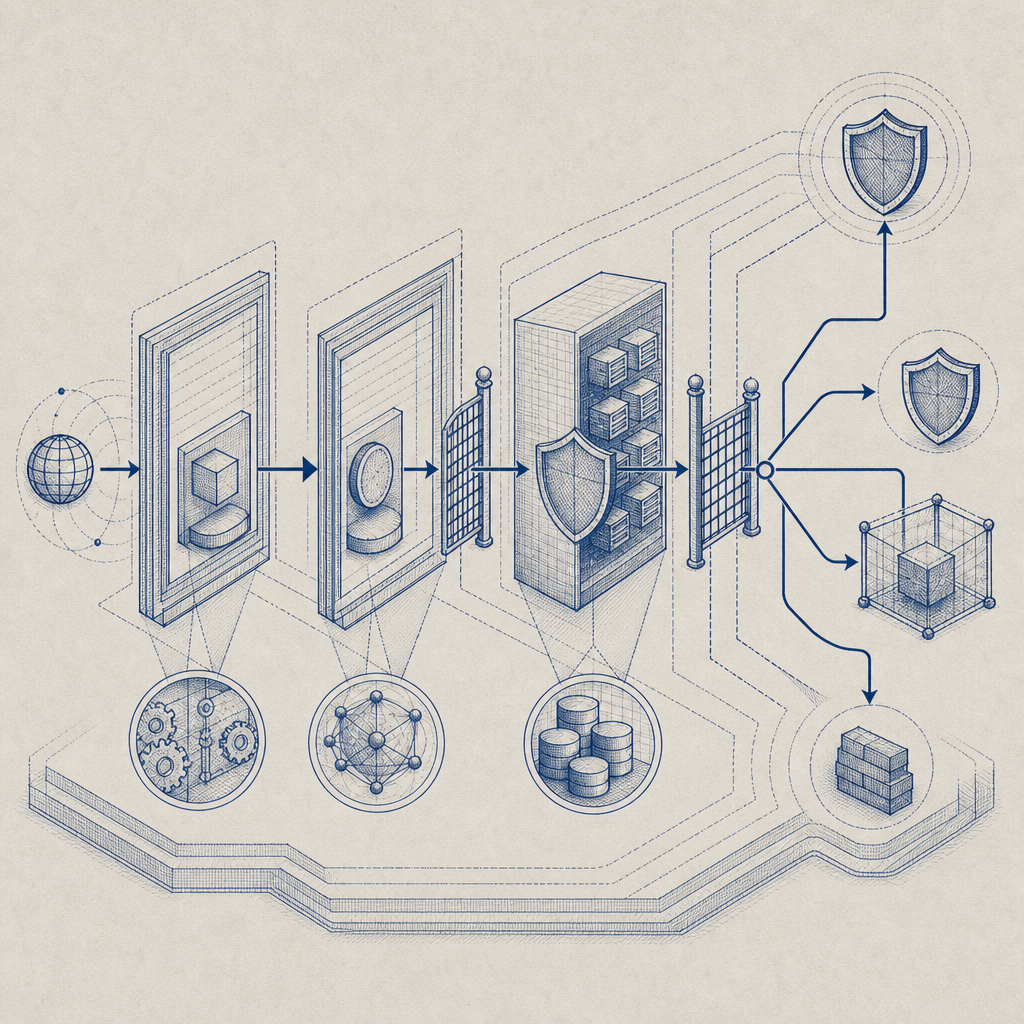
Choosing a detector without overcomplicating the stack
If your product is mostly web-based and already uses an edge platform, Cloudflare Turnstile may feel lightweight. If you need a familiar challenge ecosystem, reCAPTCHA and hCaptcha are still common choices. If you’re building across web plus native apps and want a tighter first-party validation flow, a service like CaptchaLa can reduce integration sprawl.
The better question is not “which detector is strongest?” but “which one gives me the clearest trust chain?” That chain should answer:
- What signal was collected?
- What challenge, if any, was shown?
- What token was issued?
- Where was it validated?
- What policy decided the outcome?
When those answers are clear, your bot defense is easier to test, easier to audit, and easier to improve. When they’re vague, teams end up tweaking thresholds blindly while abuse continues somewhere else.
Where to go next
If you’re evaluating bot detection for a real product, start with the docs and map the validation flow to one sensitive route first. Then expand to other pages once you’ve measured false positives and abuse reduction. See docs for implementation details or review pricing to match your traffic plan.