
A bot detector doesn't care whether the automated request comes from a scrapy Python script or a ChatGPT plugin browsing your site on a user's behalf — it cares whether the client behaves like a real human. That distinction has become harder to draw as AI agents, ChatGPT's browsing capabilities, and autonomous LLM tools send traffic that looks increasingly legitimate. Understanding how modern bot detection works — and where it struggles against AI-driven clients — is the starting point for any team trying to protect a form, API, or content paywall.
Why AI Agents Complicate Traditional Bot Detection
Classic bot detection relied on a handful of signals: missing or spoofed user-agent strings, no mouse movement, suspiciously fast form completion, and IP addresses tied to known data-center ranges. Most of those signals weaken when the client is a polished AI agent.
ChatGPT's browsing tool, for example, sends real browser-style headers and respects robots.txt. Autonomous agents built on frameworks like LangChain or AutoGPT often run inside actual Chromium instances via Playwright or Puppeteer, producing genuine browser fingerprints, real TLS handshakes, and plausible interaction timing. The result: purely passive fingerprinting catches far fewer automated clients than it did three years ago.
What still works is a layered approach that combines:
- Behavioral biometrics — micro-patterns in pointer movement, scroll velocity, and keystroke cadence that headless browsers replicate poorly even when they try to introduce artificial jitter.
- Challenge-response verification — an interactive or invisible CAPTCHA that requires the client to solve a task the server can cryptographically verify, rather than just asserting "I am human."
- Token validation on the server — checking that the pass token issued after a successful challenge is fresh, bound to the correct session, and has not been reused.
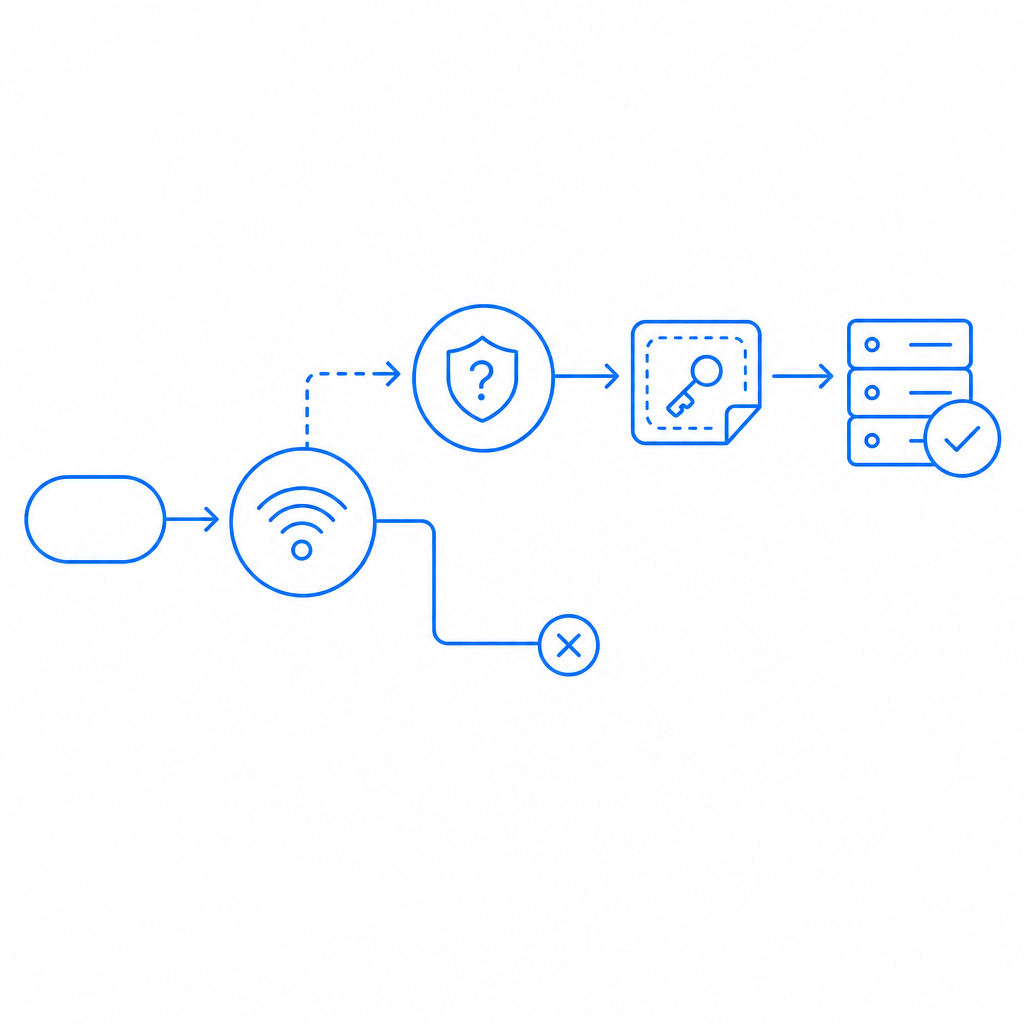
How CAPTCHA Fits Into a Bot Detector Stack
CAPTCHA is not a complete bot detector by itself — it is the challenge layer that sits inside a broader detection pipeline. When passive signals are inconclusive, the system escalates to a visible or frictionless challenge. If the challenge is passed, a signed token is issued; the server validates that token before processing the request.
Here is what that server-side validation looks like when using CaptchaLa:
// Go: validate a pass token returned by the frontend widget
package main
import (
"bytes"
"encoding/json"
"net/http"
)
type ValidateRequest struct {
PassToken string `json:"pass_token"`
ClientIP string `json:"client_ip"`
}
func verifyCaptcha(passToken, clientIP string) (*http.Response, error) {
body, _ := json.Marshal(ValidateRequest{
PassToken: passToken,
ClientIP: clientIP,
})
req, _ := http.NewRequest(
"POST",
"https://apiv1.captcha.la/v1/validate",
bytes.NewBuffer(body),
)
// Authenticate with your app credentials
req.Header.Set("X-App-Key", "YOUR_APP_KEY")
req.Header.Set("X-App-Secret", "YOUR_APP_SECRET")
req.Header.Set("Content-Type", "application/json")
client := &http.Client{}
return client.Do(req)
}The pass_token is single-use and expires quickly, so a replay attack — where an AI agent harvests a valid token and reuses it across many requests — fails automatically. This pattern is independent of the front-end framework; CaptchaLa ships native SDKs for Web (JS, Vue, React), iOS, Android, Flutter, and Electron, plus server-side packages captchala-go and captchala-php for the validation step.
Comparing Common CAPTCHA / Bot-Detection Services
When teams evaluate a bot detector, they typically shortlist a few well-known providers alongside newer options. Here is a straightforward comparison on the dimensions that matter most for AI-traffic scenarios:
| Feature | reCAPTCHA v3 | hCaptcha | Cloudflare Turnstile | CaptchaLa |
|---|---|---|---|---|
| Invisible / frictionless mode | Yes | Yes | Yes | Yes |
| Interactive challenge fallback | Limited | Yes | No | Yes |
| Server-side token validation API | Yes | Yes | Yes | Yes |
| First-party data only | No | Partial | Yes | Yes |
| Native mobile SDKs | No | No | No | Yes (iOS, Android, Flutter) |
| Free tier (monthly solves) | Yes (unmetered) | Yes | Yes | 1,000 / mo |
reCAPTCHA v3 is ubiquitous and well-understood by bot authors, which means AI agents often have ready-made workarounds. Cloudflare Turnstile is frictionless and integrates tightly with Cloudflare's broader network signals, but it has no interactive fallback for high-risk actions. hCaptcha offers a privacy-focused alternative with a healthy challenge library. CaptchaLa is a smaller, independent option that focuses on mobile-native and first-party-data use cases — worth evaluating if your traffic skews toward apps rather than web pages.
No single provider is a silver bullet against determined AI agents. The token-validation pattern described above is what converts any of these CAPTCHAs from a "check the box" UX step into a cryptographically enforced gate.
What "Bot Detector ChatGPT" Actually Means for Defenders
If you searched for "bot detector ChatGPT," you might be trying to answer one of two questions: Can ChatGPT pass your CAPTCHA? or How do I detect traffic sent by ChatGPT agents on my site?
For the first question: OpenAI's products generally respect robots.txt and identify themselves via user-agent strings like GPTBot for the crawler and ChatGPT-User for the browsing plugin. You can block or rate-limit those user agents at the CDN or WAF layer before a CAPTCHA is even reached. The harder case is third-party agents that deliberately mask their identity.
For the second question, the honest answer is that no passive signal alone is reliable. The practical defense is:
- Block known AI-crawler user agents via
robots.txtand server rules for endpoints that don't serve public content. - Require a CAPTCHA challenge token on any action that has economic or data value (account creation, checkout, content download).
- Validate that token server-side on every request — not just at login.
- Monitor pass-rate anomalies: a spike in successful tokens from a narrow IP range or during off-hours is a detection signal in itself.
- Consider rate-limiting per validated session rather than per IP, since AI agents often route through residential proxies to avoid IP-based blocks.
This combination catches the vast majority of automated AI traffic without requiring you to accurately classify every request as "human" or "bot" — a classification problem that is genuinely unsolved for the most sophisticated agents.
Where to Go Next
If you want to dig into implementation details, the docs cover widget integration for all supported SDKs and the full server-token issuance flow (POST https://apiv1.captcha.la/v1/server/challenge/issue) for server-to-server scenarios. If you're evaluating whether the free tier (1,000 validations/month) or a Pro plan fits your volume, the pricing page breaks down the tiers. The most important step, regardless of which provider you choose, is closing the gap between the front-end challenge and the server-side token check — that gap is where AI agents currently slip through most often.